un cambio de paradigma en la arquitectura de datos
Los avances tecnológicos, las crecientes exigencias de las empresas y las normativas (como el RGPD y la CCPA) son los principales impulsores de la evolución de la arquitectura de datos.
En la actualidad, se están aplicando diferentes modelos y esquemas de arquitectura :
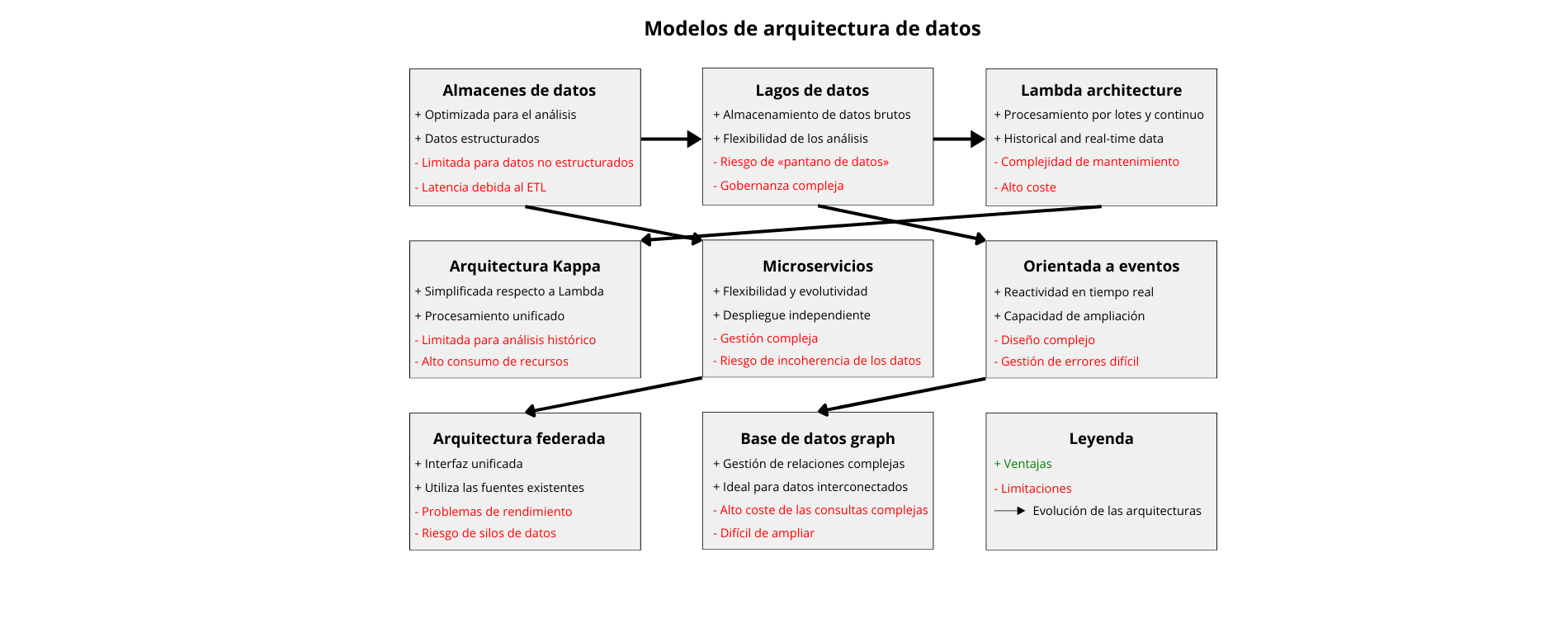
Almacenes de datos tradicionales
Repositorios centralizados para datos estructurados, optimizados para consultas analíticas e informes. Los almacenes de datos suelen adoptar un enfoque de esquema de escritura, en el que los datos se estructuran y transforman antes de cargarse en el almacén. Los almacenes de datos tradicionales más populares son Oracle Exadata, IBM Netezza y Teradata.
Límites:
- Volúmenes masivos de datos generados por las aplicaciones
- Dificultades de adaptación a formatos de datos semiestructurados o no estructurados
- Los procesos ETL pueden introducir latencia, lo que dificulta el suministro de información en tiempo real
Lagos de datos
Repositorios centralizados que almacenan datos sin procesar, no estructurados o semiestructurados a gran escala. A diferencia de los almacenes de datos, los lagos de datos permiten a las organizaciones almacenar los datos en su formato original y realizar diversos tipos de análisis, como el análisis exploratorio, el aprendizaje automático y las consultas ad hoc. Las tecnologías más populares para crear lagos de datos incluyen Apache Hadoop, Apache Spark y Amazon S3.
Límites:
- Sin una gobernanza adecuada, los lagos de datos pueden convertirse en pantanos de datos, dificultando la búsqueda y la confianza en los datos pertinentes.
- La gestión y organización de un gran volumen de datos en bruto en un lago de datos requiere una planificación minuciosa y la gestión de los metadatos.
- Almacenar datos brutos sin preprocesar puede acarrear problemas de calidad de los datos, ya que requiere un esfuerzo adicional para su limpieza y transformación.
Arquitectura Lambda
Enfoque híbrido que combina el procesamiento por lotes y el procesamiento continuo para gestionar tanto los datos históricos como los datos en tiempo real. Normalmente consta de tres capas:
- Una capa por lotes para almacenar y procesar los datos históricos,
- Una capa de velocidad para gestionar los datos en tiempo real,
- Una capa de servicio para consultar y servir los resultados.
Apache Kafka, Apache Hadoop y Apache Spark se utilizan habitualmente en las arquitecturas Lambda.
Límites:
- Implementar y mantener las capas por lotes y de velocidad separadas pueden introducir complejidad en la arquitectura.
- Garantizar la consistencia entre las capas por lotes y de velocidad puede ser difícil y puede requerir mecanismos de sincronización adicionales.
- La gestión de múltiples capas y tecnologías aumenta la sobrecarga operativa y los costes de mantenimiento.
Arquitectura Kappa
Una versión simplificada de la arquitectura Lambda que utiliza exclusivamente el procesamiento de flujo para los datos en tiempo real y por lotes. Elimina la necesidad de capas de procesamiento separadas, lo que se traduce en una arquitectura más optimizada y evolutiva.
Límites:
- Dado que la arquitectura Kappa se basa principalmente en el procesamiento de flujo, el análisis de los datos históricos puede ser limitado en comparación con la arquitectura Lambda.
- El procesamiento de todos los datos en tiempo real puede consumir muchos recursos y puede requerir una infraestructura evolutiva para gestionar las cargas de trabajo máximas.
Arquitectura de microservicios
Descomposición de las aplicaciones en pequeños servicios independientes que pueden desarrollarse, desplegarse y ampliarse de forma autónoma. Cada microservicio suele tener su propia base de datos, y los datos se intercambian entre los servicios a través de API. La arquitectura de microservicios ofrece flexibilidad, evolutividad y resiliencia, pero también presenta inconvenientes relacionados con la coherencia y la gestión de los datos.
Límites:
- Mantener la coherencia de los datos entre varios microservicios puede ser difícil, especialmente en sistemas distribuidos.
- La gestión de un gran número de microservicios introduce una complejidad operativa, especialmente en lo que respecta a la implementación, la supervisión y la depuración.
- La duplicación de los datos entre varios microservicios implica riesgos de incoherencia y problemas de sincronización.
Arquitectura orientada a eventos:
La arquitectura orientada a eventos se basa en la producción, la detección, el consumo y la reacción a los eventos. Los eventos se generan desde varias fuentes y pueden desencadenar acciones en tiempo real. Las arquitecturas orientadas a eventos son perfectas para escenarios que requieren capacidad de respuesta y evolutividad.
Límites:
- El diseño de sistemas orientados a eventos es complejo y requiere una reflexión profundizada sobre el origen de los eventos, su distribución y su coherencia final.
- La gestión y el procesamiento de los eventos en tiempo real introducen complejidades en la gestión de los errores y la recuperación.
- La ampliación de las arquitecturas basadas en eventos para gestionar grandes volúmenes de eventos requiere una infraestructura robusta y capacidades de supervisión.
Arquitectura federada
Los datos se mantienen descentralizados en varios sistemas o ubicaciones, pero se puede acceder a ellos a través de una interfaz unificada. Este enfoque permite a las organizaciones aprovechar las fuentes de datos existentes sin centralizar el almacenamiento de datos.
Límites:
- El acceso a los datos desde múltiples fuentes puede introducir problemas de latencia y rendimiento, especialmente para consultas complejas.
- Las arquitecturas federadas pueden perpetuar los silos de datos si no se diseñan e implementan correctamente, limitando el intercambio y la integración de los datos.
- Las arquitecturas federadas pueden plantear problemas de seguridad, sobre todo en lo que respecta a los controles de acceso a los datos y los mecanismos de autenticación.
Arquitectura de base de datos graph
Los datos se representan en forma de nodos, aristas y propiedades, lo que los hace muy adecuados para gestionar relaciones complejas y datos interconectados. Las arquitecturas de bases de datos de grafos suelen utilizarse en aplicaciones como las redes sociales, los motores de recomendación y los sistemas de detección de fraudes.
Límites:
- Las consultas complejas que recorren grandes grafos pueden ser costosas desde el punto de vista del cálculo y requerir técnicas de optimización.
- El diseño de un modelo de datos gráfico eficaz requiere una reflexión minuciosa sobre las relaciones y la estructura de los datos.
- La ampliación de las bases de datos gráficas para manejar grandes gráficos con millones de nodos y aristas puede resultar difícil.
Como puede verse en este macroanálisis, los modelos tradicionales se enfrentan a obstáculos para su evolución debido al aumento constante del volumen y la complejidad de los datos. Es más, las arquitecturas centralizadas a menudo conducen a la creación de silos de datos y cuellos de botella, lo que dificulta la accesibilidad y la colaboración dentro de la organización. Además, aplicar políticas coherentes de gobernanza de datos en toda la organización puede resultar arduo para estas arquitecturas centralizadas. Por otra parte, estos modelos son vulnerables a los puntos únicos de fallo y pueden tener dificultades para mantener la disponibilidad de los datos en caso de interrupción. Ante estos retos, ¿qué tipo de arquitectura puede superar eficazmente estas limitaciones?
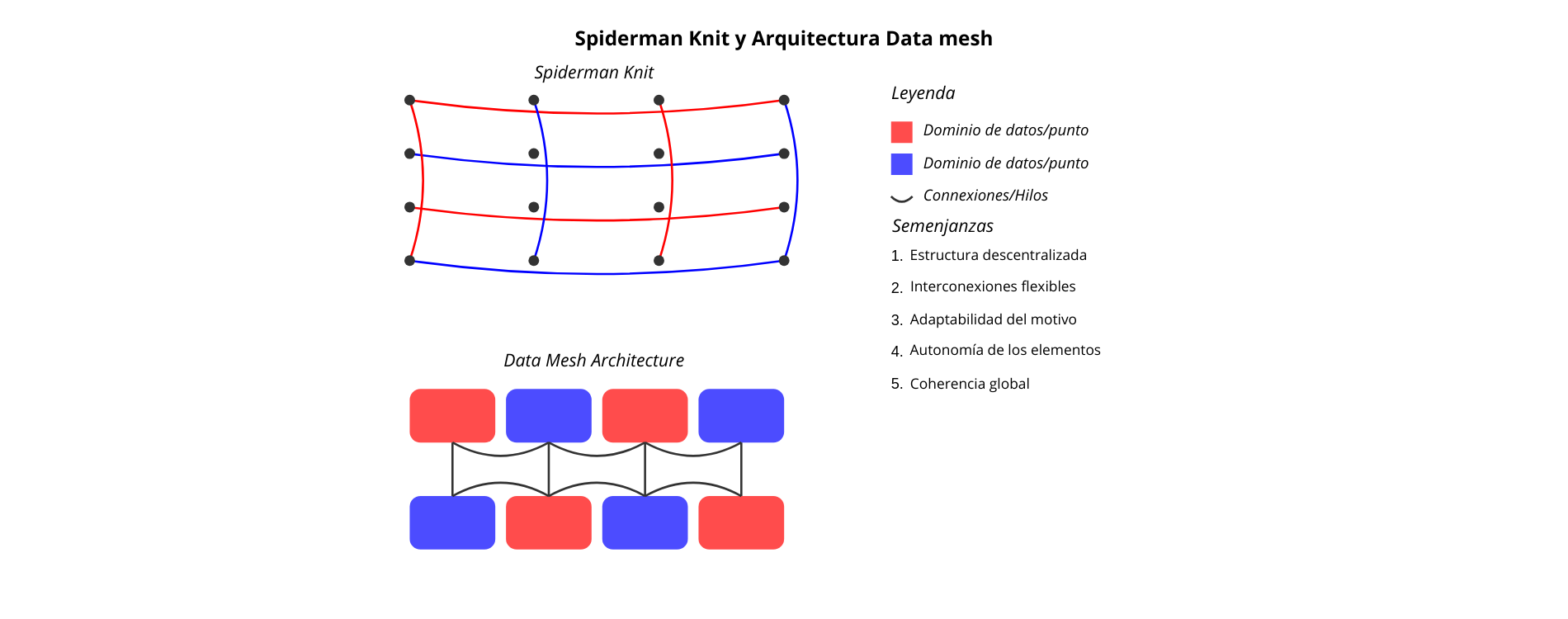
Spiderman Knit y arquitectura Data Mesh
«Spiderman Knit» hace referencia a un estilo o técnica de punto utilizado para diseñar un tejido que recuerda a las telarañas o al traje de Spiderman. Esta técnica implica el uso de bucles o puntos entrelazados para crear una textura que se asemeje a la compleja estructura asociada al superhéroe. El punto Spiderman implica trabajar en diferentes partes del tejido simultáneamente para crear un motivo, en lugar de adoptar un enfoque centralizado. Los motivos de punto Spiderman varían en complejidad y diseño, ofreciendo una gran flexibilidad y adaptabilidad. Esta descripción pone de relieve las características interconectadas, descentralizadas y adaptables del «Spiderman Knit».
Como analogía, consideremos la distribución de datos entre dominios específicos, cada uno responsable de sus propios productos y servicios de datos. Al igual que los hilos entrelazados de una prenda de Spiderman forman un motivo coherente, esta arquitectura se basa en productos y servicios de datos interconectados para satisfacer las necesidades de datos de la organización. Al adoptar un enfoque descentralizado de la propiedad y la gestión de los datos, los equipos específicos de cada dominio pueden hacerse cargo de sus propios datos y crear productos de datos adaptados a sus necesidades. Este enfoque descentralizado fomenta la agilidad, la capacidad de ampliación y la innovación, así como la flexibilidad y la creatividad necesarias para diseñar un motivo inspirado en Spiderman. Esta arquitectura puede adaptarse a una gran variedad de fuentes de datos, formatos y casos de uso, lo que permite a las organizaciones adaptar su infraestructura de datos a sus necesidades específicas.
Se trata de la arquitectura DATA MESH, basada en principios fundamentales que favorecen la descentralización, la interoperabilidad y la autonomía de los dominios de datos.
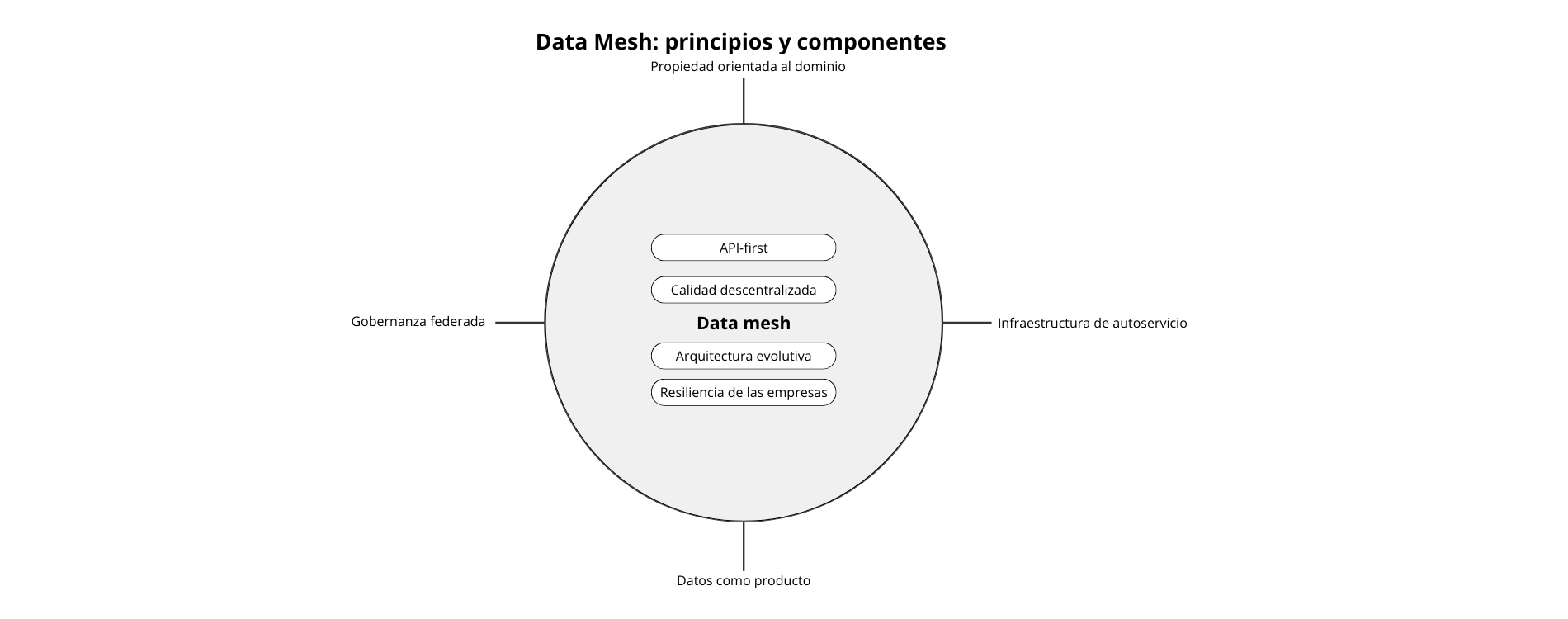
Principios básicos
Se sientan las bases fundamentales de la malla de datos para guiar su desarrollo e implantación. Están diseñados para hacer frente a las dificultades de las arquitecturas de datos centralizadas tradicionales y promover un enfoque descentralizado y centrado en el dominio de la gestión de datos.
1. Propiedad de los datos orientada al dominio: La propiedad y la gobernanza de los datos están descentralizadas, y los equipos de cada dominio asumen la responsabilidad de los datos que producen y utilizan. Cada equipo de dominio se encarga de definir y gestionar sus propios productos y servicios de datos.
2. Infraestructura de datos de autoservicio: Los equipos de dominio tienen acceso de autoservicio a la infraestructura y las herramientas de datos, lo que les permite crear, desplegar y operar productos de datos de forma independiente. Este enfoque reduce la dependencia con respecto a los equipos de datos centralizados y fomenta la agilidad y la autonomía.
3. Los datos como producto: Los datos se consideran un producto, producido, consumido y mejorado por los equipos del dominio. Este cambio de perspectiva incita a los equipos de dominio a centrarse en la creación de valor a través de sus productos y servicios de datos, del mismo modo que lo hacen con los productos de software.
4. Arquitectura y plataforma para la malla de datos: La organización invierte en una arquitectura y una plataforma de malla de datos que proporciona la infraestructura, las herramientas y las normas para ayudar a los equipos de dominio a gestionar sus productos de datos. Esto incluye funcionalidades como la detección de datos, la gestión de metadatos y la gobernanza de datos.
5. Gobernanza de datos federada: La gobernanza de los datos es federada, con equipos de dominio responsables de definir y aplicar políticas de gobernanza adaptadas a sus necesidades específicas. Esto permite a los equipos de dominio conservar su autonomía garantizando al mismo tiempo el cumplimiento de las normas y reglamentos de la organización.
6. Reflexión sobre el producto y diseño centrado en el usuario: Los equipos de dominio adoptan un enfoque de reflexión sobre el producto y principios de diseño centrados en el usuario para desarrollar productos de datos que satisfagan las necesidades de sus usuarios. Esto conlleva comprender las necesidades de los usuarios, iterar en función de los comentarios y priorizar las características que ofrecen más valor.
7. Enfoque API-first: Los productos de datos exponen API que permiten a otros equipos del dominio descubrir, acceder e integrar datos de forma estandarizada e interoperable. Esto fomenta la reusabilidad, la interoperabilidad y la colaboración entre dominios.
8. Calidad descentralizada y observabilidad de los datos: Los equipos de dominio son responsables de garantizar la calidad, fiabilidad y observabilidad de sus productos de datos. Esto implica implantar controles de calidad de los datos, supervisar los pipelines de datos y proporcionar visibilidad sobre el uso y el rendimiento de los datos.
9. Arquitectura evolutiva y mejora continua: La arquitectura de malla de datos está diseñada para evolucionar con el tiempo en respuesta a la evolución de las necesidades empresariales y los avances tecnológicos. Se insta a los equipos de dominio a experimentar, iterar y mejorar continuamente sus productos e infraestructuras de datos.
Al adherirse a estos principios básicos, las organizaciones pueden disfrutar de las ventajas de un enfoque descentralizado y centrado en el dominio de la gestión de datos, como una mayor agilidad, capacidad de ampliación e innovación, al tiempo que superan los retos de las arquitecturas de datos centralizadas, como los silos de datos, la complejidad y las limitaciones de la evolutividad.
Hacia la resiliencia empresarial y la convergencia de los datos
Al adoptar los principios del Data Mesh, las organizaciones pueden fortalecer la resiliencia empresarial descentralizando la propiedad de los datos, posibilitando las capacidades de autoservicio, estableciendo una gobernanza federada, adoptando un enfoque centrado en API, implementando una arquitectura evolutiva y fomentando una cultura basada en la reflexión relativa a los productos de datos.
Así es como funciona:
1. Propiedad descentralizada de los datos:
Al descentralizar la propiedad de los datos, la malla de datos permite a cada equipo de dominio gestionar sus propios productos de datos. Este enfoque reduce la dependencia con respecto a los equipos y sistemas centralizados, aumentando la resiliencia de la organización frente a las perturbaciones. En caso de problema en un dominio, los demás pueden seguir funcionando de forma autónoma, limitando el impacto en el conjunto de la empresa.
2. Infraestructura de datos de autoservicio
Como parte de la malla de datos, se fomenta el acceso de autoservicio a la infraestructura y las herramientas de datos para los equipos de dominio. Este enfoque permite a los equipos ajustar rápidamente sus productos e infraestructuras de datos a las necesidades cambiantes de la empresa, sin tener que depender de recursos centralizados. Las capacidades de autoservicio mejoran la agilidad y posibilitan una respuesta más rápida a las perturbaciones, ayudando a la empresa a mantener sus operaciones en las épocas difíciles.
3. Gobernanza federada:
Con un enfoque de gobernanza federada, cada equipo de dominio se encarga de definir y aplicar políticas de gobernanza adaptadas a sus necesidades específicas. De este modo se garantiza el cumplimiento de la normativa y las normas de la organización, al tiempo que se satisfacen diversos requisitos comerciales. La gobernanza federada reduce los cuellos de botella y mejora la capacidad de la organización para adaptarse a los cambios o perturbaciones reglamentarias.
4. Enfoque API-First:
Como parte de la malla de datos, se está fomentando un enfoque API-First para la integración de los datos, lo que facilita el intercambio y el acceso a los datos entre diferentes sistemas y equipos. Las API proporcionan interfaces normalizadas para compartir datos, facilitando la integración e interoperabilidad transparentes entre los productos de datos. Este enfoque facilita la colaboración y permite a la empresa ajustar rápidamente sus procesos y sistemas en respuesta a las perturbaciones o los nuevos requisitos.
5. Arquitectura evolutiva:
La arquitectura Data Mesh está diseñada para evolucionar en función de las necesidades cambiantes de la empresa y de los avances tecnológicos. Se insta a los equipos de dominio a experimentar, iterar y mejorar permanentemente sus productos e infraestructuras de datos. Este enfoque evolutivo fomenta la innovación y la adaptabilidad, garantizando que la organización siga siendo resiliente ante la evolución de los retos y oportunidades.
6. Reflexión sobre los productos de datos:
Al tratar los datos como un producto, se insta a los equipos de dominio a concentrarse en la creación de valor para sus usuarios. Este cambio de mentalidad fomenta el diseño centrado en el usuario, la iteración rápida y la mejora continua de los productos de datos. Al proporcionar productos de datos valiosos que satisfagan las necesidades de los usuarios, la organización puede resistir mejor las perturbaciones y mantener su resiliencia. Estos principios permiten a los equipos adaptarse rápidamente a las perturbaciones, los cambios normativos y la evolución de los requisitos comerciales, garantizando que la organización siga siendo resiliente y competitiva en un entorno en rápida evolución.
Desafíos de adopción
Aunque la arquitectura de malla de datos ofrece muchas ventajas, su adopción conlleva una serie de desafíos a los que pueden tener que enfrentarse las organizaciones.
1. Cambio cultural:
Las arquitecturas de datos centralizadas tradicionales suelen implicar un control y una toma de decisiones centralizados, mientras que una malla de datos fomenta la descentralización y la autonomía entre equipos de dominio. Convencer a las partes interesadas y a los equipos para que adopten este cambio cultural puede resultar difícil y requerir un fuerte liderazgo y esfuerzos de gestión del cambio.
2. Competencias y especialización:
La adopción de una arquitectura de malla de datos requiere que los equipos de dominio cuenten con las competencias y la especialización necesarias en ámbitos como la ingeniería de datos, la gobernanza de datos y la gestión de productos. Es posible que las organizaciones tengan que invertir en acciones de formación y desarrollo para garantizar que los equipos de dominio tengan las capacidades necesarias para gestionar eficazmente sus productos de datos.
3. Complejidad tecnológica:
La implantación de una arquitectura de malla de datos implica el despliegue y la gestión de un conjunto diverso de tecnologías, incluidas la infraestructura de datos, las herramientas y las plataformas. Integrar estas tecnologías y garantizar su interoperabilidad puede resultar complejo y requerir una importante inversión inicial en infraestructura y especialización.
4. Gobernanza y seguridad de los datos:
La descentralización de la propiedad de los datos plantea desafíos relacionados con la gobernanza de los datos, la seguridad y el cumplimiento. Garantizar la coherencia de las políticas de gobernanza y los controles de seguridad entre los equipos de dominio, al tiempo que se posibilita la flexibilidad y la autonomía, puede ser todo un reto. Las organizaciones deben establecer marcos de gobernanza y medidas de seguridad robustas para mitigar los riesgos asociados a la gestión descentralizada de los datos.
5. Calidad y coherencia de los datos:
Mantener la calidad y la coherencia de los datos entre los equipos del dominio puede resultar difícil, sobre todo cuando los datos proceden de sistemas y fuentes dispares. Garantizar la calidad, fiabilidad y coherencia de los datos a la vez que se posibilita la autonomía y la flexibilidad requiere una meticulosa planificación, supervisión y colaboración entre los equipos del dominio.
6. Integración e interoperabilidad:
Garantizar una integración y una interoperabilidad transparentes y al mismo tiempo posibilitar la autonomía y el acceso de autoservicio requiere API, formatos de datos y protocolos de comunicación normalizados. Las organizaciones deben invertir en tecnologías y prácticas de integración para facilitar el intercambio de datos y la colaboración.
7. Silos organizativos:
Los equipos de dominio pueden concentrarse en exceso en sus propios productos y prioridades en materia de datos, lo que da lugar a la fragmentación y la duplicación de esfuerzos. Las organizaciones deben fomentar la colaboración y la comunicación entre los equipos de dominio para garantizar la armonización con los objetivos comerciales más amplios.
8. Gestión del cambio:
La transición a una arquitectura de malla de datos implica cambios organizativos significativos y puede toparse con la resistencia de las partes interesadas, acostumbradas a los enfoques centralizados tradicionales. La gestión eficaz del cambio, la comunicación y el compromiso de las partes interesadas son esenciales para superar la resistencia y garantizar el éxito de la adopción de la arquitectura de malla de datos.
Hacer frente a estos retos requiere un enfoque holístico que implica armonizar la cultura organizativa, desarrollar las competencias y los conocimientos necesarios, aplicar medidas de gobernanza y seguridad robustas, fomentar la colaboración y la comunicación, y gestionar eficazmente el cambio.
Conclusión: el potencial transformador de la malla de datos en el rediseño de la arquitectura de datos
En resumen, la arquitectura de malla de datos responsabiliza a los equipos de dominio, fomenta la colaboración y garantiza que los datos evolucionen en sincronía con las necesidades de la empresa y los avances tecnológicos. Se trata de un cambio de paradigma que potencia la agilidad y la evolutividad en la gestión de los datos. Aunque la adopción de una arquitectura de malla de datos puede plantear dificultades, las ventajas potenciales en términos de agilidad, innovación y resiliencia la convierten en una inversión rentable para las organizaciones que desean aprovechar plenamente su potencial en lo que respecta a los datos.
«Data Mesh es un enfoque sociotécnico descentralizado para gestionar y acceder a los datos analíticos a gran escala». Zhamak Dehghani
Glosario del Data Mesh
- Data Mesh (Malla de datos): Un enfoque arquitectónico descentralizado para la gestión de los datos a gran escala.
- Propiedad de datos orientada al dominio: Principio según el cual los equipos de un dominio específico son responsables de los datos que producen y utilizan.
- Infraestructura de datos de autoservicio: Herramientas y plataformas que permiten a los equipos de dominio gestionar sus datos de forma autónoma.
- Datos como producto: Un concepto que trata los datos como un producto en sí mismo, con su propio ciclo de vida y valor.
- Gobernanza de datos federada: Enfoque de gobernanza en el que los equipos de dominio definen sus propias políticas respetando las normas de la organización.
- API-first: Un enfoque que propicia la creación de API para el acceso a los datos y la integración entre los dominios.
- Calidad descentralizada de los datos: Responsabilidad de los equipos de dominio para garantizar la calidad de sus propios datos.
- Arquitectura evolutiva: Un diseño flexible que permite a la infraestructura de datos adaptarse a las necesidades cambiantes de la empresa.
- Resiliencia de las empresas: Capacidad de una organización para adaptarse y sobrevivir frente a las perturbaciones.
- Convergencia de datos: Proceso de integración y armonización de datos procedentes de distintas fuentes.
- Silos organizativos: Aislamiento de los equipos o departamentos que dificulta la colaboración y el intercambio de información.
- Datos estructurados: Datos organizados según un formato predefinido, generalmente almacenados en bases de datos relacionales. Son fáciles de buscar y analizar (por ejemplo, hojas de cálculo, bases de datos SQL).
- Datos semiestructurados: Datos que tienen una cierta estructura organizativa, pero que no son tan rígidos como los datos estructurados. Pueden contener etiquetas o marcadores para separar elementos (por ejemplo, archivos XML, JSON).
- Datos no estructurados: Datos que no tienen una estructura predefinida ni están organizados de forma predeterminada. Son más difíciles de analizar y procesar con los métodos tradicionales (por ejemplo, texto libre, imágenes, vídeos).
- Procesamiento por lotes: Método de procesamiento de datos en el que se recoge un gran volumen de datos durante un periodo de tiempo y luego se procesan en una sola operación. Se utiliza para tareas que no requieren resultados en tiempo real.
- Procesamiento continuo: Un enfoque del procesamiento de datos en el que éstos se procesan en cuanto llegan, lo que permite analizarlos y reaccionar casi en tiempo real.
- Procesamiento de flujos: Método de procesamiento continuo de datos, especialmente diseñado para gestionar flujos de datos en tiempo real. Permite analizar y reaccionar ante los datos a medida que llegan, sin almacenarlos necesariamente de forma permanente.