Que es DevOps ?
En enfoque DevOps se caracteriza por la combinación del desarrollo de software (Dev) y la administración de infraestructuras informáticas (Ops). Su aplicación requiere la implementación de un flujo de trabajo de supervisión estratégica. Esta supervisión ayuda a garantizar una elevada disponibilidad y rendimiento de los servicios en la nube en entornos que cambian rápidamente.
Con este enfoque, la supervisión es un elemento esencial tanto para los equipos de desarrollo (Dev) como para los de operaciones (Ops). Permite esbozar de manera eficiente las actividades de un sistema de información. Sin supervisión, no sería posible reaccionar de forma automática y con rapidez para corregir cualquier anomalía en la aplicación. En este artículo, revisamos la estrategia y las herramientas que hemos aplicado para satisfacer estas necesidades.
-
- En OpenShift, las tareas cron se supervisan con la solución de supervisión de Prometheus configurada en Openshift.
- En las máquinas virtuales del entorno local, algunas aplicaciones web ya se supervisan mediante la solución de supervisión de Grafana.
Érase una vez en Davidson…
En Davidson alojamos, como muchos, las aplicaciones desarrolladas por Twister [enlace] (nuestra DSI) en dos tipos de entornos:
- Nube (Openshift)
- «Local»
Las aplicaciones alojadas en ambos tipos de entorno ejecutan programaciones cron: tareas cron de Openshift en el nivel de las aplicaciones alojadas en la nube de Openshift y programaciones cron del sistema que se ejecutan en el nivel de infraestructura local.
Estas programaciones cron son las que permiten planificar la ejecución de una tarea, así como su periodicidad.
Técnicamente, las programaciones cron varían según el tipo de alojamiento:
- OpenShift utiliza tareas cron de OpenShift. La tarea cron crea una plantilla en lenguaje YML que produce una tarea/pod de Kubernetes.
- En las máquinas virtuales de la infraestructura local, los comandos de Linux inician los sistemas de las programaciones cron. Cada programación cron se compone de tres elementos: el script que se debe ejecutar, el comando que ejecuta el script y la acción o el registro del script.
La supervisión también varía según el tipo de entorno:
Sin embargo, no existe una forma unificada para supervisar simultáneamente el estado de estas programaciones cron. En otras palabras, si falla la ejecución de una tarea cron o un cron de sistema, el equipo de Ops no podrá obtener rápidamente esta información centralizada para ambos tipos de cron.
Para mejorar la supervisión de las aplicaciones, nuestro proyecto tiene dos objetivos:
- Asegurar el seguimiento y la visualización del estado de estos dos tipos de programación cron de forma centralizada.
- Visualizar en un solo panel el último estado de cada programación cron.
Elección de herramientas
Openshift
Openshift es una plataforma híbrida en la nube de código abierto de RedHat. Se ha concebido para el desarrollo, la implementación y la gestión de aplicaciones. Proporciona a los desarrolladores un entorno integrado para crear e implementar contenedores Docker y luego gestionarlos con la plataforma de orquestación de código abierto de Kubernetes.
Con esta combinación, Openshift permite que cualquier aplicación se ejecute en cualquier lugar donde se admitan contenedores Docker.
Cuando los desarrolladores envían sus códigos a Openshift, este último es responsable de organizar cómo y cuándo se ejecutan las aplicaciones. Asimismo, permite a los equipos de desarrollo corregir, afinar y evolucionar sus aplicaciones.
Openshift también proporciona un catálogo en línea. Algunas de las categorías más usadas incluyen la gestión de contenedores, el desarrollo de aplicaciones móviles, los sistemas operativos, los lenguajes de programación, el registro, la supervisión o la gestión de bases de datos.
Con una comunidad de colaboradores de gran envergadura, Openshift presenta muchas ventajas para nosotros:
- el desarrollo acelerado de aplicaciones;
- varias formas de gestionar y automatizar los contenedores;
- la escalabilidad automática según recursos, tráfico y condiciones a definir;
- la duplicación de la cantidad de pods para mejorar el rendimiento de la aplicación;
- la posibilidad de efectuar un rollback;
- las ventajas de la contenedorización frente a las máquinas virtuales (portabilidad, gestión reducida, contenedores más ligeros y eficientes, etc.).
Supervisión de OpenShift
En cuanto a las soluciones de supervisión, las empresas pueden elegir entre varias herramientas DevOps útiles para facilitar el proceso, entre las que encontramos: SolarWinds, Nagios, Zabbix, Prometheus, Graphite, Centreon, etc.
Las necesidades que se deben tener en cuenta al seleccionar una solución de supervisión son las siguientes:
- la identificación de problemas y el envío de alertas al administrador;
- el registro y el rastreo de información y el historial en tiempo real;
- la creación de paneles personalizados.
Para satisfacer estas necesidades, hemos seleccionado la stack de supervisión de Prometheus y Grafana. Las ventajas son:
- Prometheus y Grafana se pueden utilizar como servicios complementarios.
- Combinados, proporcionan una sólida base de datos de series temporales, con una excelente visualización de los datos.
- Estas dos herramientas se utilizan ampliamente para supervisar aplicaciones en entornos basados en contenedores.
- Prueba de la madurez de esta solución, Prometheus y Grafana constituyen la stack de supervisión predeterminada de OpenShift.
Prometheus
Prometheus es una herramienta creada por la plataforma SoundCloud. Se trata de un sistema de supervisión y de alertas de código abierto que se considera una base de datos de series temporales en tiempo real con lenguaje de consulta PromQL. Prometheus se usa ampliamente en los flujos de trabajo modernos de DevOps, especialmente para infraestructuras basadas en contenedores y microservicios.
La siguiente imagen muestra la arquitectura de Prometheus:
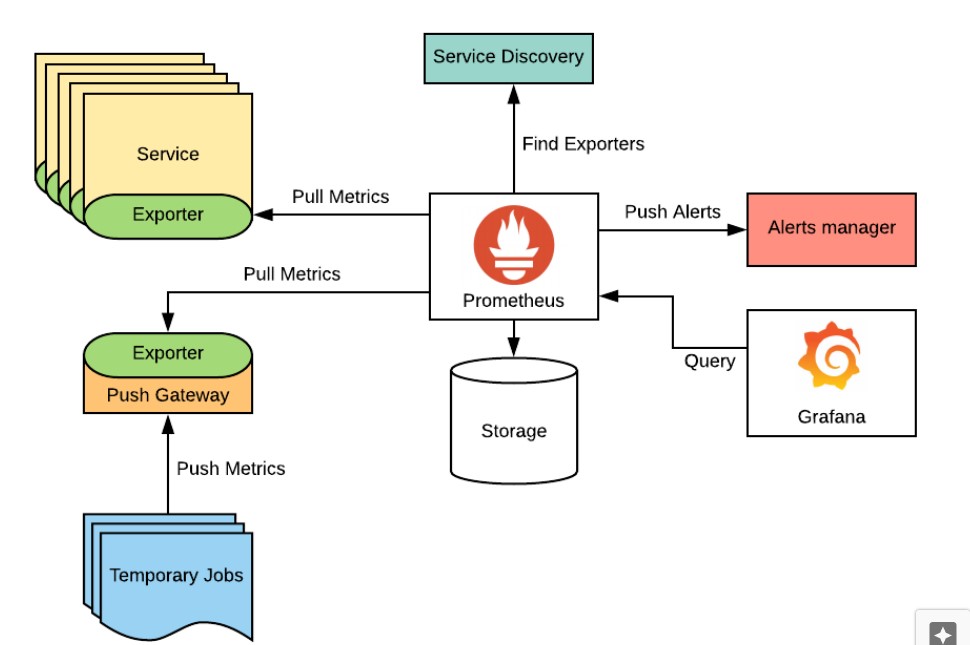
- El servidor Prometheus: recopila las métricas en forma de datos de series temporales a partir de los nodos y las almacena en su base de datos.
- Exportadores: estos componentes permiten exponer las métricas de Prometheus y mostrarlos a través de un endpoint, según un formato específico (en PromQL). Bibliotecas de cliente: Prometheus almacena datos en un formato de serie temporal y solo acepta datos en este formato. En algunos casos de uso, donde no existen exportadores bien definidos para exponer las métricas, debe efectuarse manualmente un proceso de «instrumentación» que permite definir métricas personalizadas que Prometheus puede recopilar.
- PushGateway: en ocasiones trabajos cuya duración es más corta que el intervalo de scraping (o el periodo de recopilación de métricas) de Prometheus. El push Prometheus interviene para permitir que este tipo de tareas expongan sus métricas a Prometheus.
- Alert Manager: esta entidad gestiona las alertas enviadas por las aplicaciones de cliente. Se encarga de enrutar las alertas a canales de comunicación como correo electrónico, Slack, Discord, etc.
- Interfaz de usuario web: este componente se diseña para visualizar y exportar datos de Prometheus mediante la ejecución de consultas PromQL. Aprovecha las reglas del Alert Manager, la configuración, la maquinaria de destino, etc.
- Service Discovery: para minimizar las configuraciones, Prometheus realiza un descubrimiento automático de los servicios en ejecución, por ejemplo, en entornos de Kubernetes.
· Grafana
Grafana es una solución de código abierto que analiza datos, extrae métricas procedentes de múltiples aplicaciones y supervisa aplicaciones usando un panel personalizable.
Grafana puede conectarse a varias fuentes de datos, denominadas bases de datos, como Graphite, Prometheus, InfluxDB, ElasticSearch, MySQL, PostgreSQL, etc. Por último, el panel de Grafana permite cargar múltiples filas y paneles y el usuario también puede visualizar los resultados de diferentes fuentes de datos simultáneamente.
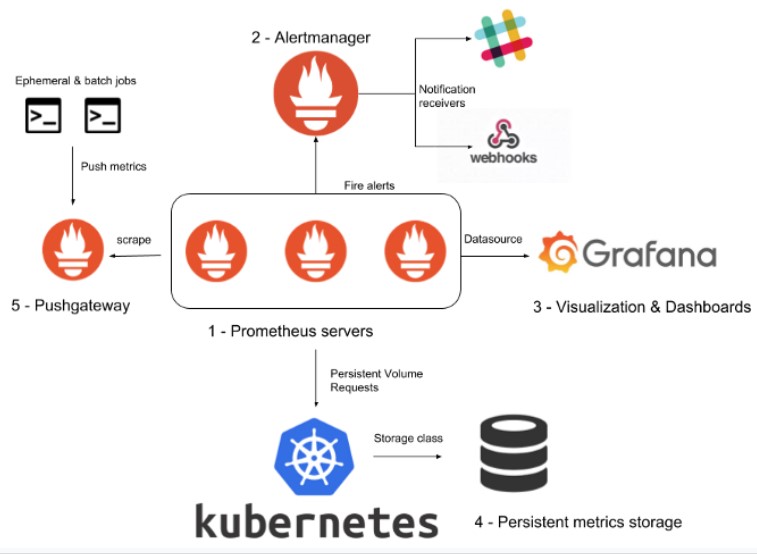
¿Por qué combinar Prometheus y Grafana?
En primer lugar, ambas herramientas son de código abierto y están ampliamente adoptadas. Se pueden implementar fácilmente para las instalaciones básicas y son muy eficientes. También tienen soporte para la versión «empresa».
En segundo lugar, Prometheus & Grafana tienen una gran comunidad de colaboradores, lo que ayuda a anticipar una gran cantidad de casos de uso y permite encontrar soluciones adaptadas a diversos problemas.
Por último, además de estar empaquetados por defecto con OpenShift, ya los utilizamos en nuestro clúster para supervisar otros artículos. Por otro lado, Prometheus ya está configurado para supervisar el estado de las tareas cron de Openshift.
Arquitectura de la aplicación
existente
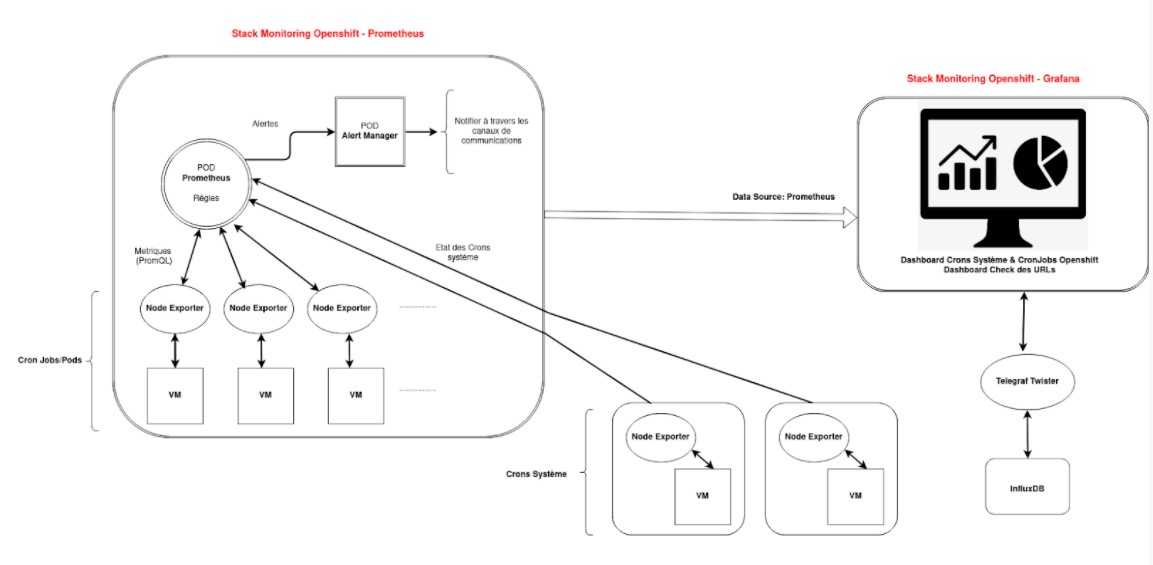
Prometheus y Grafana supervisan las aplicaciones y las tareas cron de OpenShift.
Supervisión de tareas cron de OpenShift
El funcionamiento es el siguiente:
- cada tarea cron crea un trabajo y posteriormente un pod;
- en OpenShift, el pod de Prometheus está conectado a estos otros pods;
- estos pods envían sus métricas a Prometheus. Así, Prometheus recibe información sobre el estado de las tareas cron.
Para implementar esta configuración, procedimos de la siguiente manera:
- configurar un exportador de nodos para cada máquina virtual en el clúster de Openshift;
- configurar reglas con base en métricas;
- configurar alertas a nivel de Prometheus y Alert Manager.
Supervisión de las aplicaciones
El funcionamiento es el siguiente:
- La stack de supervisión de Grafana está configurada con la fuente de datos Telegraf Twister.
- Telegraf envía información relacionada con las respuestas HTTP de diferentes aplicaciones.
- Esta información se analiza mediante consultas InfluxQ.
- Un panel muestra, para cada aplicación, la siguiente información:
- La última respuesta HTTP para cada aplicación.
- La respuesta en milisegundos de cada aplicación.
Objetivo
A este existente incorporamos dos elementos:
- Supervisión del estado de las programaciones cron de sistema que se ejecutan en máquinas virtuales fuera del clúster de Openshift.
- Supervisión de la duración de la no respuesta de las diferentes aplicaciones y la generación de alertas.
Supervisión de las programaciones cron de sistema
Para supervisar el estado de estas programaciones cron de sistema que se ejecutan en máquinas virtuales fuera del clúster de Openshift, procedemos de la siguiente manera:
- Conectar las máquinas virtuales al pod de Prometheus.
- En las máquinas virtuales, configurar los exportadores de nodos para enviar el estado de la programación cron de sistema mediante métricas a Prometheus.
- En Prometheus, aprovechando estas métricas, configurar reglas para activar alertas.
- En un panel de Grafana, visualizar el estado más reciente de cada tarea cron de Openshift y cada programación cron de sistema.
Supervisión de las aplicaciones
Para supervisar la duración de la no respuesta de las distintas aplicaciones y la generación de alertas, utilizaremos la última respuesta HTTP de cada aplicación:
- un panel de Grafana permitirá la visualización de la duración de la no respuesta de cada aplicación;
- en caso de no respuesta de una de las aplicaciones, Grafana generará una alerta.
Réalisation & résultats
Logros y resultados
Supervisión de tareas cron de Openshift y programaciones cron de sistema
Vinculación de máquinas virtuales al pod de Prometheus
Hemos vinculado el pod de Prometheus a máquinas virtuales que ejecutan programaciones cron de sistema fuera del clúster de Openshift.
A continuación se muestra un ejemplo con «eos». Se trata de una aplicación interna desarrollada por el equipo de Twister en PHP para la gestión de la base de datos central de los empleados de Davidson.
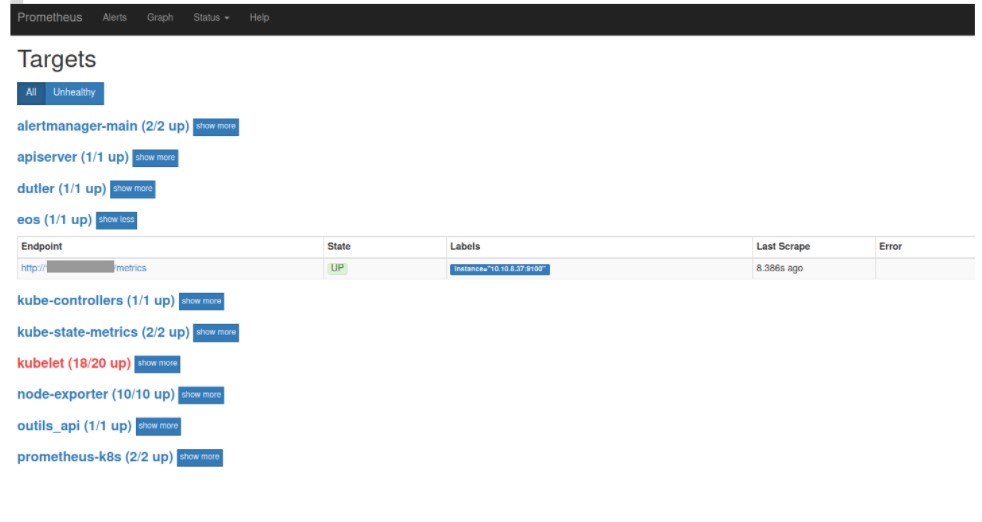
Informes de métricas
En segundo lugar, cada máquina virtual agregada debe configurarse para enviar sus métricas sobre las programaciones cron de sistema.
Este es el paso más importante, porque Prometheus no tiene métricas por defecto para informar sobre el estado de las programaciones cron de sistema. En general, es necesario configurar un exportador pero, para las programaciones cron, no existe ningún exportador disponible.
Compensamos esta ausencia de la siguiente manera:
- Configuración de un exportador de nodos en cada máquina virtual fuera del clúster de Openshift.
- Incorporación de máquinas de destino en la configuración básica del servidor de Prometheus.
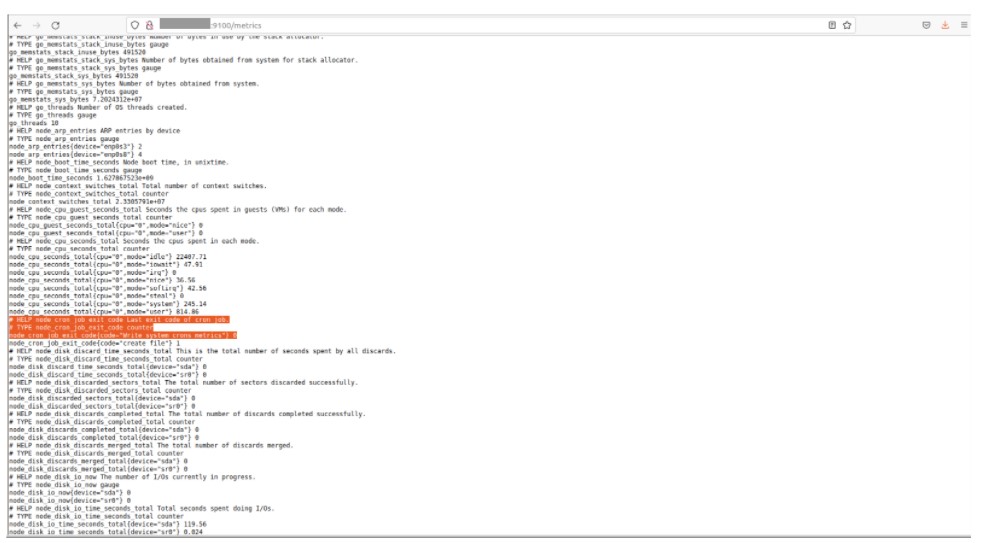
- Implementación de un script Bash que personalizará y enviará métricas que describen el estado de las programaciones cron de sistema (0 para éxito, 1 para fracaso).
- Configuración del Node Textfile Collector para analizar todas las métricas registradas.
- Configuración de una regla que se utilizará para mostrar alertas en caso de que la ejecución de una programación cron falle.
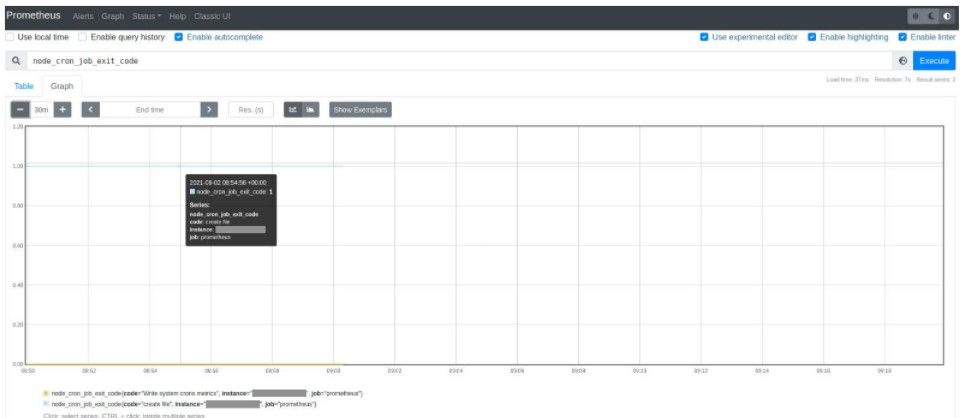
La siguiente imagen muestra una métrica configurada correspondiente al estado de una programación cron de sistema marcada con 0.
Prometheus brinda la capacidad de visualizar, mediante una curva, la información que transmite la métrica.
Alertas
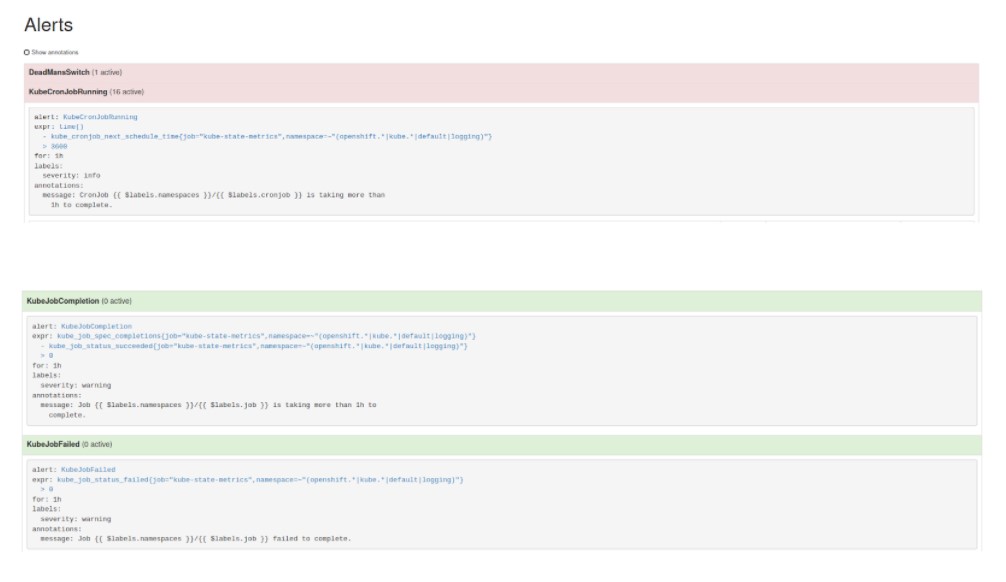
Tras la configuración de una regla, en caso de que la programación cron no se ejecute correctamente, se mostrará una alerta:
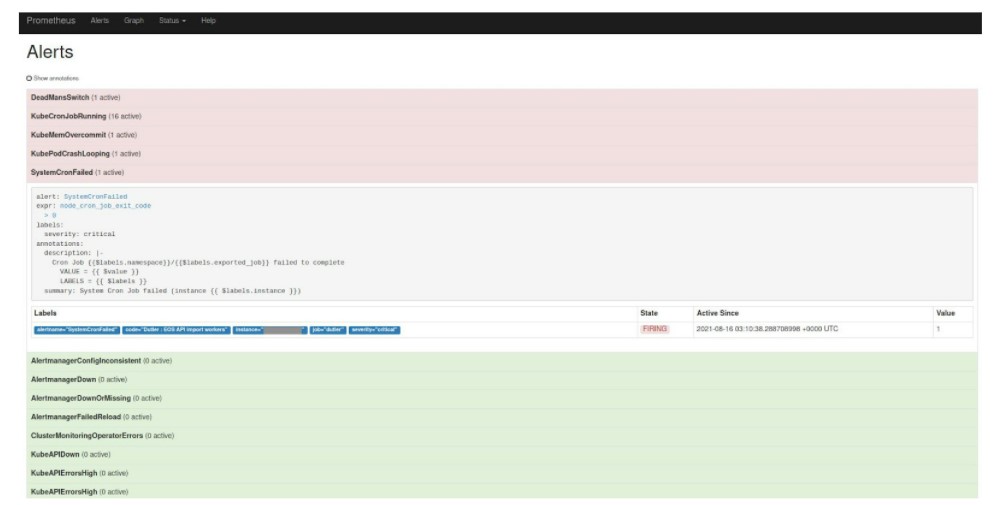
También existen reglas/alertas ya configuradas (frente a la existente) para informar del estado de tareas cron de Openshift.
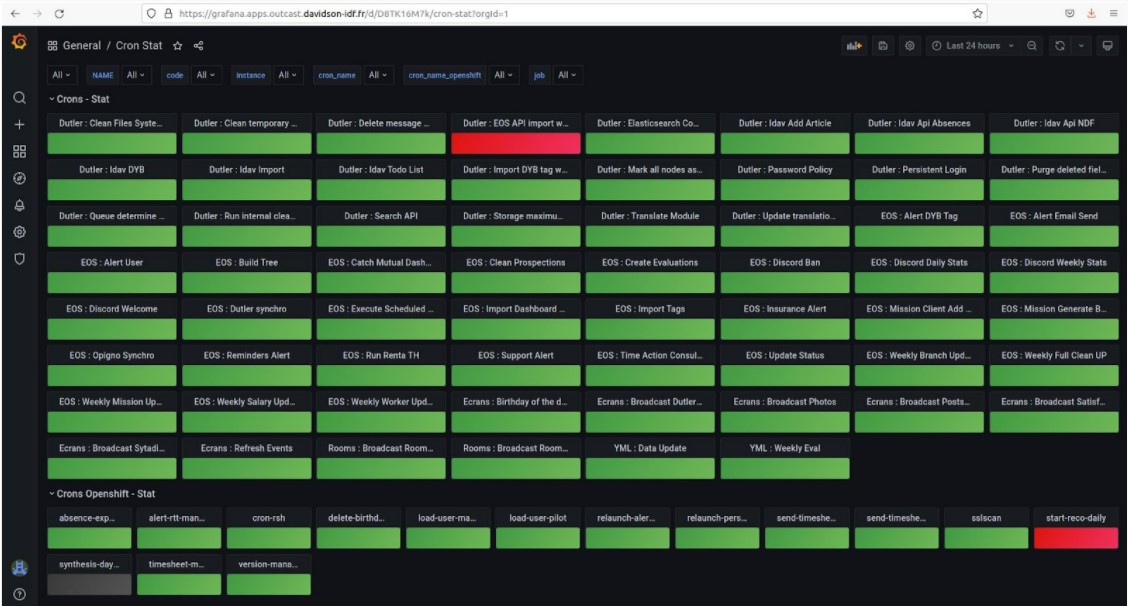
Panel
Asimismo, tenemos la posibilidad de visualizar tanto el estado de todas las programaciones cron de sistema como el estado de las tareas cron de Openshift en un panel de Grafana.
El panel a continuación se compone de dos «filas». Cada una corresponde a una categoría de cron y cada cron se presenta en forma de Panel.
- La fila «Crons – Stat» muestra todas las programaciones cron de sistema.
- La fila «Crons Openshift – Stat» muestra todas las tareas cron de Openshift.
- En verde, las programaciones cron que se han ejecutado correctamente.
- En rojo, las programaciones cron que han fracasado.
En cuanto a la gestión de alertas, tras el proceso en caso de incidente y las acciones que se deben emprender para garantizar un buen tratamiento, consideramos algunos puntos importantes para responder a las necesidades de nuestro proyecto: un sistema de supervisión eficaz para el equipo de Ops, que proporciona una respuesta rápida cuando falla una programación cron.
El panel se mostrará en una pantalla, frente a todo el equipo Dev & Ops.
Alert Manager de Prometheus enviará alertas para tareas cron Openshift a través de ambos canales de comunicación: correo electrónico y Discord.
A continuación se muestra un ejemplo de una alerta enviada por Alert Manager de Prometheus por correo electrónico.
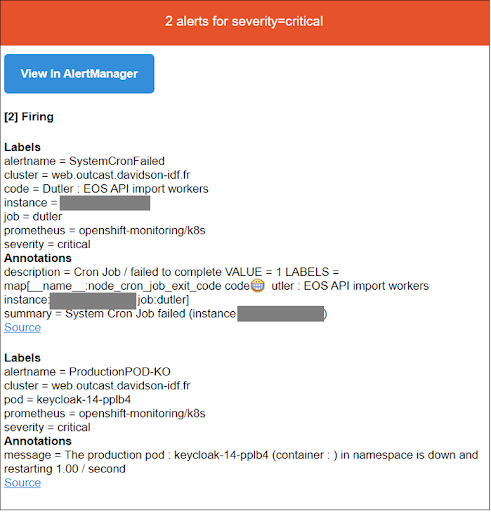
En la misma medida, y para no molestar al equipo Dev, el equipo Ops es el receptor de las alertas, en particular para realizar el primer análisis en función de la anomalía informada, que prioriza y comunica posteriormente al equipo Dev.
Supervisión de las aplicaciones
Para las aplicaciones, ya existe un panel «HTTP Response Monitoring Twister» de Grafana para visualizar:
- el estado de la última respuesta HTTP de cada aplicación;
- el tiempo de respuesta en milisegundos de cada aplicación en un intervalo de tiempo determinado.
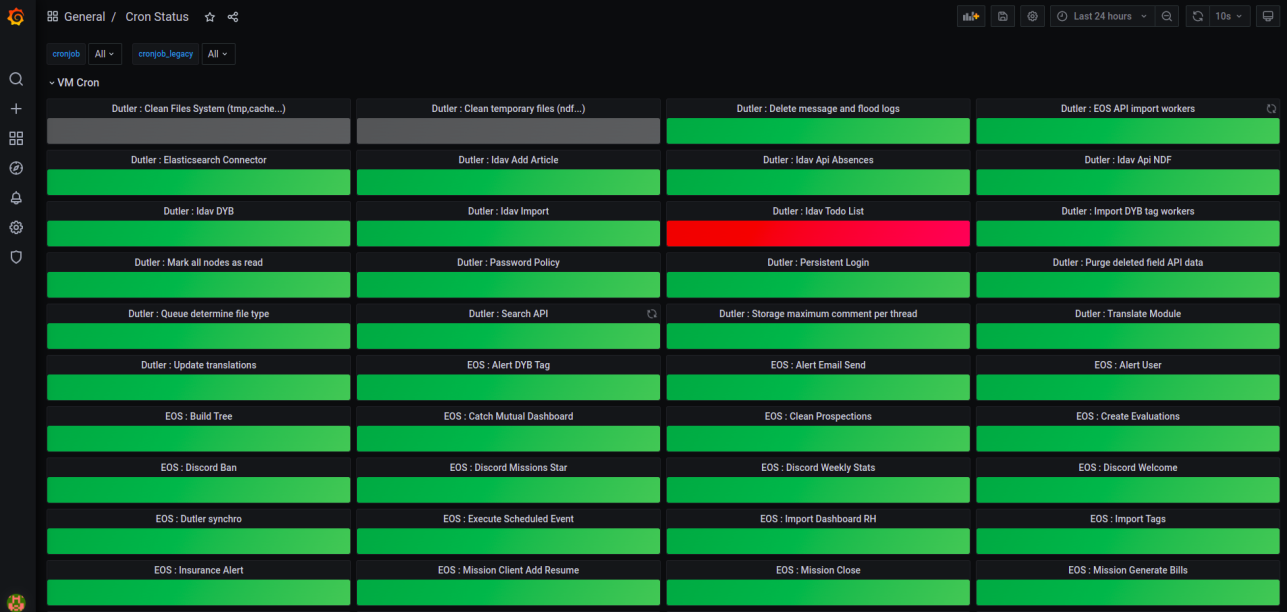
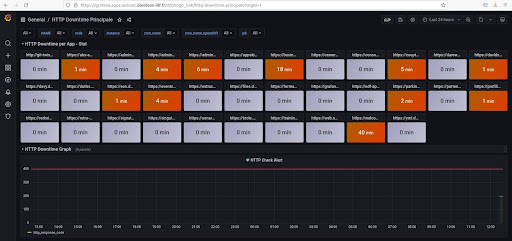
A continuación, es necesario crear otro panel de «HTTP Downtime».
- La primera fila «HTTP Downtime per App – Stat» muestra, para cada panel, el tiempo de no respuesta de una aplicación, durante un intervalo de tiempo que se seleccionará en la parte superior del panel.
- La segunda fila «HTTP Downtime Graph» permite ver las últimas 60 respuestas HTTP para cada aplicación.
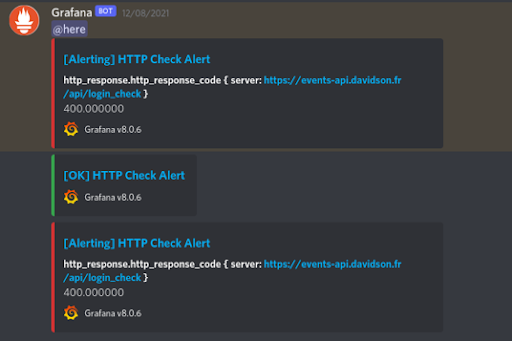
En la continuación de este proceso y de la gestión de alertas, estas medidas pueden aplicarse al Alert Manager de Grafana, que se ha configurado para enviar alertas al canal específico de Discord, en caso de que la respuesta HTTP sea igual o superior a 400.
En conclusión
En este artículo, abordamos nuestro enfoque para la supervisión DevOps, a través del cual pudimos observar los diferentes aspectos teóricos y prácticos relacionados con programaciones cron de sistema, tareas cron, Openshift, Prometheus y Grafana y cómo interactúan todos estos elementos.
Resultado
Pudimos implementar un sistema unificado para visualizar las programaciones cron que se ejecutan dentro y fuera del clúster Openshift de cara a permitir que el equipo de DevOps tome rápidamente las medidas apropiadas en caso de alertas.