1.Una breve introducción a MLOps
A) ¿Por qué MLOps?
En términos generales, MLOps es la práctica emergente de industrializar la producción de modelos de aprendizaje automático (ML, por sus siglas en inglés).
La producción de un modelo de aprendizaje automático se realiza de forma muy artesanal, especialmente cuando el volumen de datos es bajo. El método de trabajo del data scientist generalmente consiste en:
- Recopilar los datos que necesita en su puesto de trabajo
- Probar los modelos en un Notebook
- Guardar los indicadores de rendimiento en un archivo de Excel
- Comunicar el modelo a los desarrolladores y DevOps para que puedan llevarlo a producción
- Comprobar si el modelo en producción se comporta como se esperaba a través de consultas a la base de datos
Toda esta mecánica puede funcionar si se trabaja de forma individual en su proyecto con la esperanza de no encontrar nunca un problema, pero en cuanto hay que trabajar en equipo, cuando hay que gestionar cientos de algoritmos, cuando la estación de trabajo del data scientist no se inicia, o cuando este deja la empresa, esta dinámica alcanza rápidamente sus límites.
Ejemplos de preguntas que pueden surgir:
-
- ¿Cuál es la última versión de los datos que se debe utilizar?
- ¿Dónde están los datos que tanto tiempo dedicamos a etiquetar?
- ¿Hemos probado ya este o aquel algoritmo? Si es así, ¿cómo? ¿Con qué resultados?
- ¿Cuál es el Notebook que permitió generar el modelo? ¿Existe un mínimo estructurado para que sea legible y mantenible?
- ¿Cómo sé si el modelo está funcionando correctamente en la fase de producción?
Los procesos bien definidos pueden solucionar algunos de los problemas mencionados anteriormente, pero hoy en día las herramientas también pueden facilitar la vida diaria de los data scientists.

B) MLOPS en Twister
En Twister, la DSI de Davidson, trabajamos en varios proyectos de aprendizaje automático, entre ellos:
- Un chatbot disponible en la página de inicio del sitio web de Davidson https://www.davidson.fr/
- Un motor de recomendaciones que muestra una fuente de noticias personalizada en nuestra intranet
Hasta el día de hoy, no contábamos con una herramienta dedicada a MLOps, por lo que decidimos realizar un estudio de oportunidades dirigido a:
- Conocer lo que ya se ha probado, cómo, con qué resultados, para poder simplemente compartir lo que se ha hecho y facilitar la colaboración entre data scientists
- Ser capaz de reproducir experimentos pasados, lo cual es muy útil cuando se quiere partir de un proyecto o de una prueba anterior para tener una línea de base y no perder tiempo intentando reproducirla
- Almacenar modelos demasiado grandes para Git (el límite es de 100 Mb, y los modelos de procesamiento de lenguaje o procesamiento de imágenes pueden superar fácilmente este tamaño)
- Automatizar el reentrenamiento de modelos
Por ello, decidimos realizar una prueba de concepto basada únicamente en tecnologías de código abierto para industrializar nuestros proyectos de Data Science.
Nota: No hemos abordado la parte de despliegue, porque en Twister esta parte ya está automatizada gracias a Gitlab-CI/CD y OpenShift.
2. Las soluciones MLOps
Cada vez existen más soluciones y no es necesariamente fácil clasificarlas. Para averiguarlo, lo único que tienes que hacer es visitar el sitio web https://landscape.lfai.foundation/.
Algunas soluciones cubren varias necesidades, otras se enfocan en un tema específico.
Tras un análisis inicial sobre proyectos de código abierto, hemos decidido probar las siguientes herramientas:
- Herramientas generales: MLflow, Metaflow y Kubeflow
- Herramientas dedicadas a la gestión de pipelines y flujos de trabajo: Airflow y Prefect
- Herramientas dedicadas al versionado de datos: Pachyderm y DVC
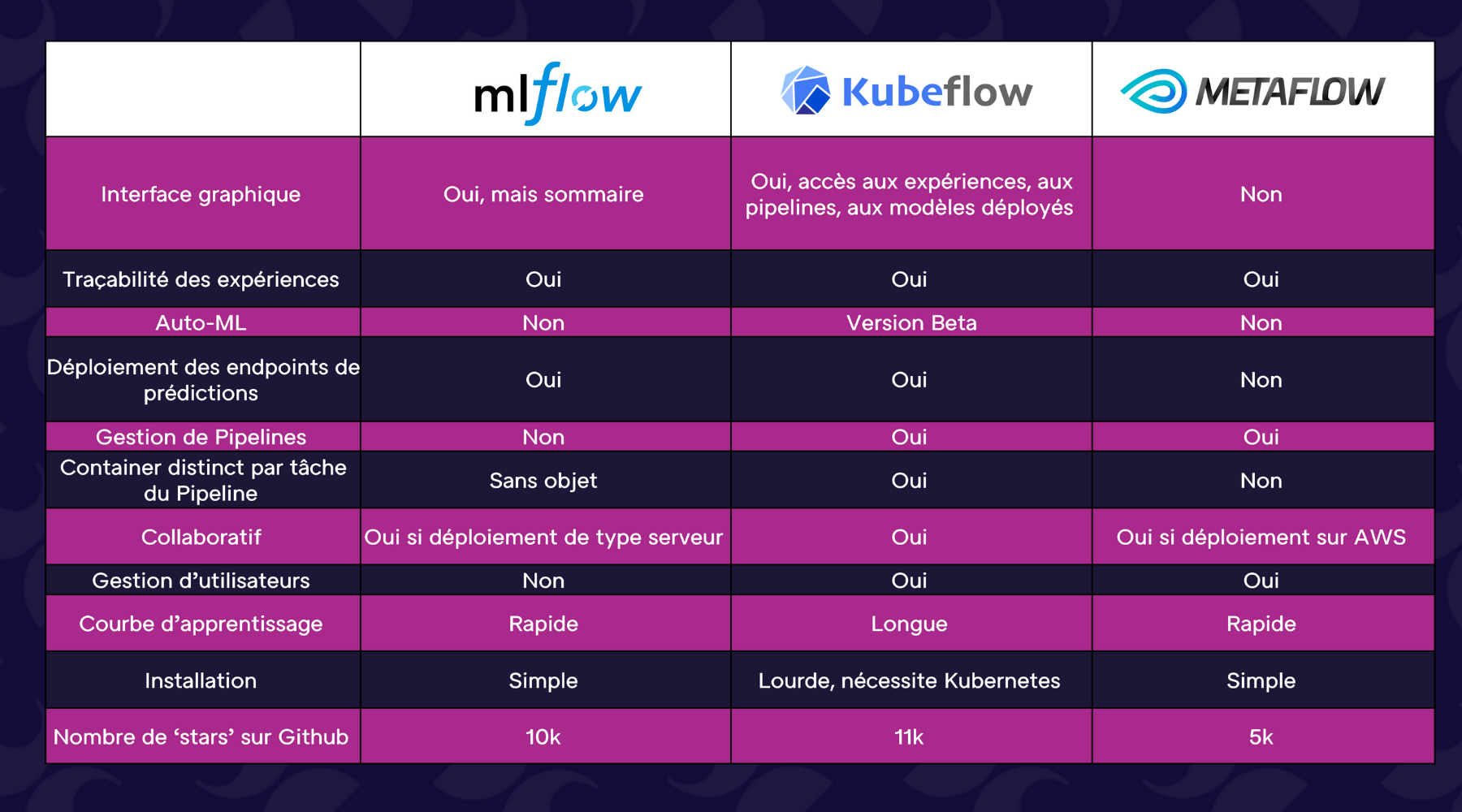
A) MLflow y Kubeflow y Metaflow
MLflow es una plataforma desarrollada por Databricks que permite administrar gran parte del ciclo de vida de un proyecto de aprendizaje automático.
Ofrece diferentes módulos:
- Un módulo para rastrear experimentos
- Un módulo para estructurar el código de su proyecto
- Un registro de modelos
- Un módulo para aplicar sus modelos
Kubeflow es una plataforma MLOps desarrollada por Google con base en una arquitectura Kubernetes. Permite principalmente:
- Administrar pipelines de aprendizaje automático
- Almacenar cada uno de los artefactos de salida de tareas para el seguimiento del experimento
- Desplegar sus modelos
Por último, Metaflow es una solución desarrollada por Netflix que permite organizar su código en forma de pipeline y rastrear experimentos.
A continuación se muestra una tabla comparativa de estas tres soluciones:
B) Airflow y Prefect
Se trata de tres herramientas que permiten administrar los pipelines, ya sean de aprendizaje automático o no.
El más conocido es Airflow, que se utiliza ampliamente en organizaciones que necesitan gestionar muchos pipelines. La interfaz gráfica es clara, es posible consultar los pipelines, relanzar tareas fallidas, programarlas… Sin embargo, es complicado de implantar (requiere un servidor para la interfaz web y un servidor para el programador) y el desarrollo de los pipelines no es intuitivo.
Prefect fue creado por uno de los fundadores de Airflow con el objetivo de simplificar la herramienta. De hecho, la creación de pipelines es muy sencilla y solo es necesaria la instalación del paquete Python. También es posible implantar un servidor para rastrear las ejecuciones de los pipelines y una interfaz gráfica. Cabe destacar que existe una versión empresarial con funciones adicionales, como la gestión de usuarios.
C) Pachyderm y DVC
Se trata de herramientas para versionar datos y para estructurar su código en forma de pipelines.
Pachyderm es muy potente, porque solo almacena las diferencias entre dos versiones del mismo conjunto de datos. Si se realiza una modificación en el conjunto de datos, el pipeline se reinicia automáticamente. Otro punto interesante es que si se modifica una tarea del pipeline, solo se volverá a ejecutar esta tarea y las siguientes. También existe una interfaz gráfica, pero esta última es de pago desde 2018.
DVC también permite versionar grandes conjuntos de datos y su punto fuerte es su facilidad de uso. De hecho, DVC usa la sintaxis de Git para versionar conjuntos de datos y recopilarlos. La desventaja es que para cada versión de DVC almacena conjuntos de datos completos, no solo diferencias.
3. Soluciones MLOps en nuestro contexto
Nuestro equipo de Data Science está formado por unas pocas personas y trabajamos en un número limitado de proyectos. Por tanto, buscamos sobre todo una solución que sea fácil de implementar, simple de operar y con una curva de aprendizaje rápida. Este último punto es fundamental, porque el equipo está en constante evolución (becarios, contratos internos, etc.). También se ha tenido en cuenta la comunidad en torno a los proyectos, su actividad y el hecho de que no sean rentables a medio plazo.
Por tanto, optamos por la siguiente stack:
- MLflow para el seguimiento del experimento y el registro de modelos
- DVC para versionado de datos
- Prefect para la gestión de pipelines
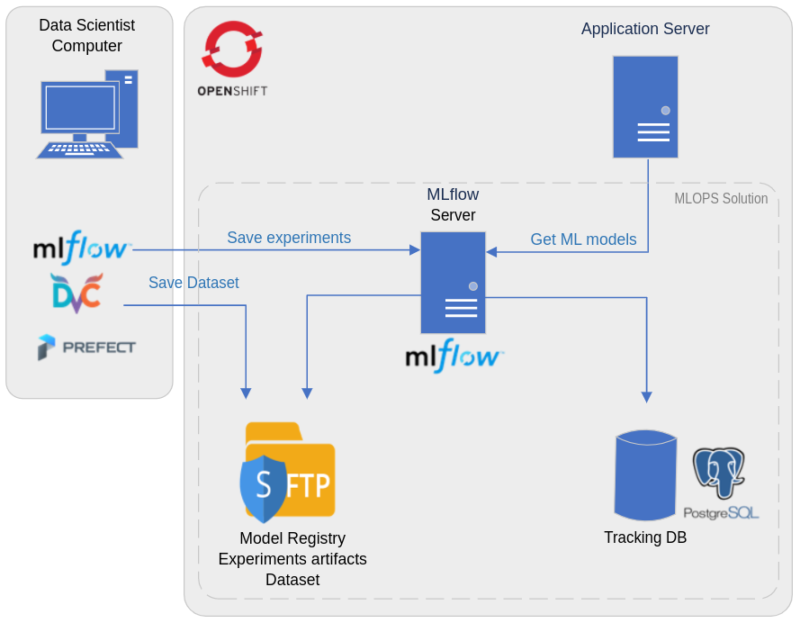
A) Arquitectura
Desde el punto de vista de la arquitectura técnica, todos los contenedores necesarios para la solución se gestionan en OpenShift, con:
- Un contenedor para el servidor Mlflow
- Un contenedor para la base de datos PostgreSQL, que se utiliza para almacenar métricas y parámetros de cada uno de los experimentos
- Un contenedor SFTP para almacenar artefactos de experimentos (como imágenes relacionadas con los resultados de los experimentos) y almacenar modelos y conjuntos de datos
B) Metodología de trabajo
Se ha revisado la metodología de trabajo de los data scientists para aprovechar al máximo las funcionalidades que ofrecen estas herramientas.
El elemento central de la nueva metodología es el compromiso de Git. De hecho, en cada experimento se debe hacer referencia al compromiso de Git, por lo que es muy fácil encontrar el código que lo produjo. Asimismo, gracias a DVC, existe un pequeño archivo de referencia de los datos utilizados y que también se añade a Git. El data scientist también puede encontrar los datos sin hacer preguntas.
Paso 1 – inicialización del proyecto
Para comenzar desde un proyecto existente, el data scientist simplemente necesita ejecutar los siguientes dos comandos para recopilar todo lo que necesita:
$ git clone projet
$ dvc pull
Si el data scientist desea comenzar desde una prueba anterior, todo lo que tiene que hacer es extraer el número de compromiso adecuado de MLflow y ejecutar los siguientes comandos:
$ git checkout -b new_branch commit_number
$ dvc pull
Por tanto, el científico de datos tiene el código y los datos para reproducir la línea de base. Las versiones de los paquetes utilizados también son importantes y se almacenan en MLflow.
Paso 2 – Realización de nuevas pruebas
El data scientist puede entonces realizar nuevos experimentos.
- Si la modificación se refiere al código (generación de funciones, nuevo modelo, nueva forma de dividir los datos), esta modificación debe ser objeto de un compromiso antes de iniciar el entrenamiento. También es posible realizar compromisos automáticos para aligerar el proceso utilizando el paquete GitPython
- Si la modificación se refiere a los parámetros del modelo, que se rastrean en MLflow, no es necesario realizar un compromiso.
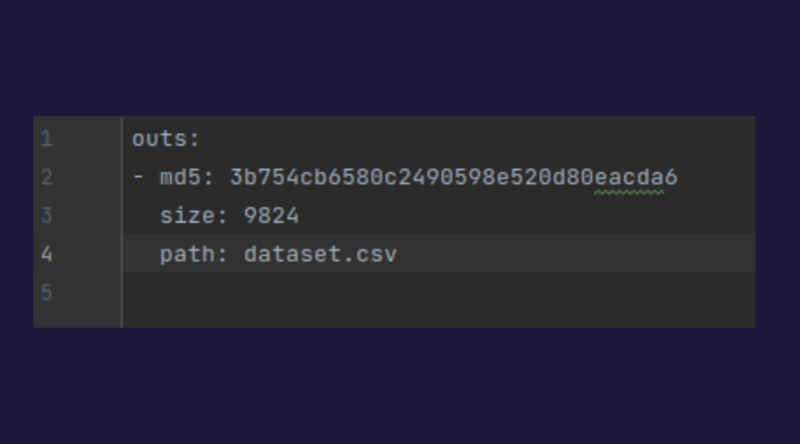
- Si la modificación se refiere al conjunto de datos, el data scientist solo debe ejecutar el comando: dvc add dataset
Ello genera un pequeño archivo con la extensión .dvc del que se muestra un ejemplo y que tendrá que comprometerse:
Además, el conjunto de datos se carga automáticamente en el servidor SFTP.
Paso 3 – Ver los resultados en MLflow
Los resultados son visibles en MLflow y se pueden comparar con los resultados obtenidos anteriormente.
A continuación se muestra la pantalla de inicio de MLflow, donde es posible acceder a todos los experimentos realizados.
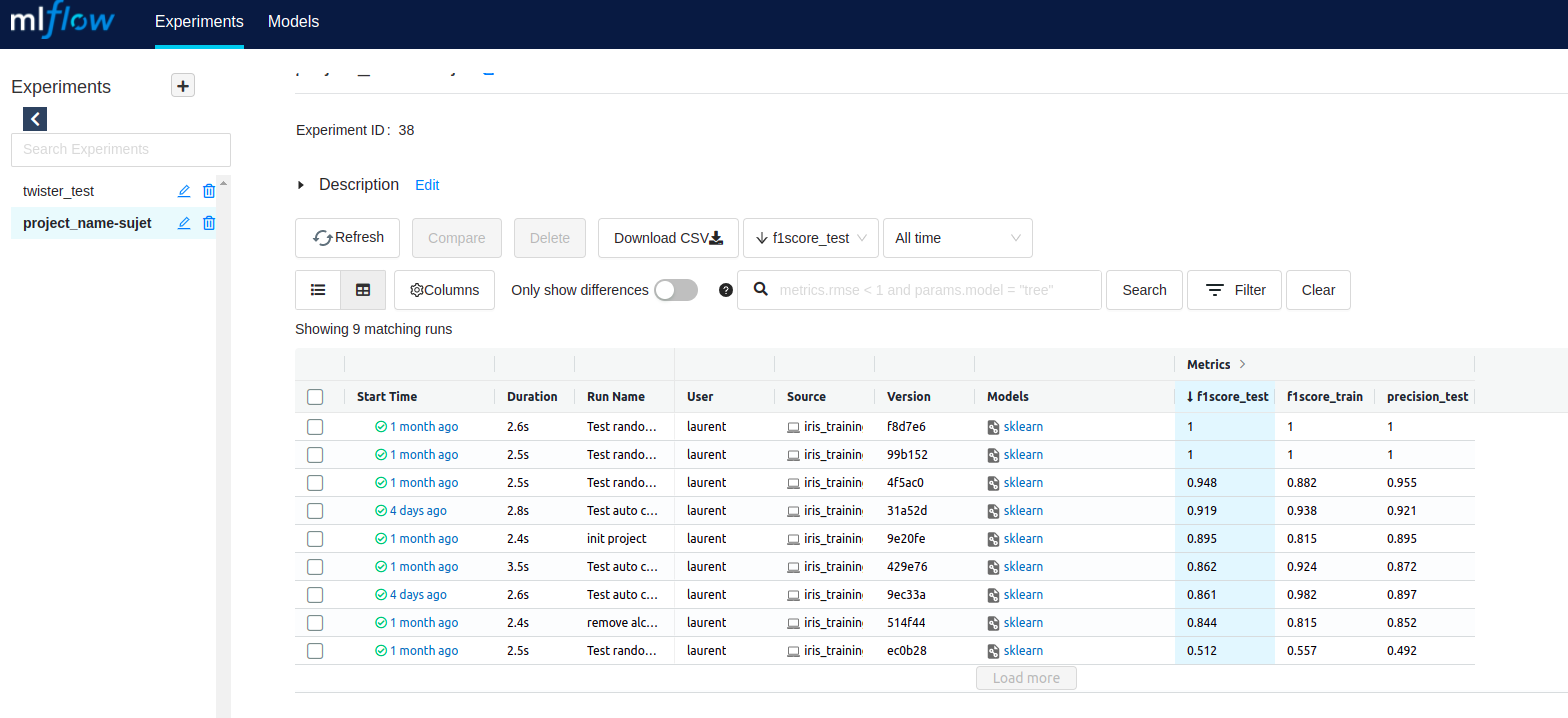
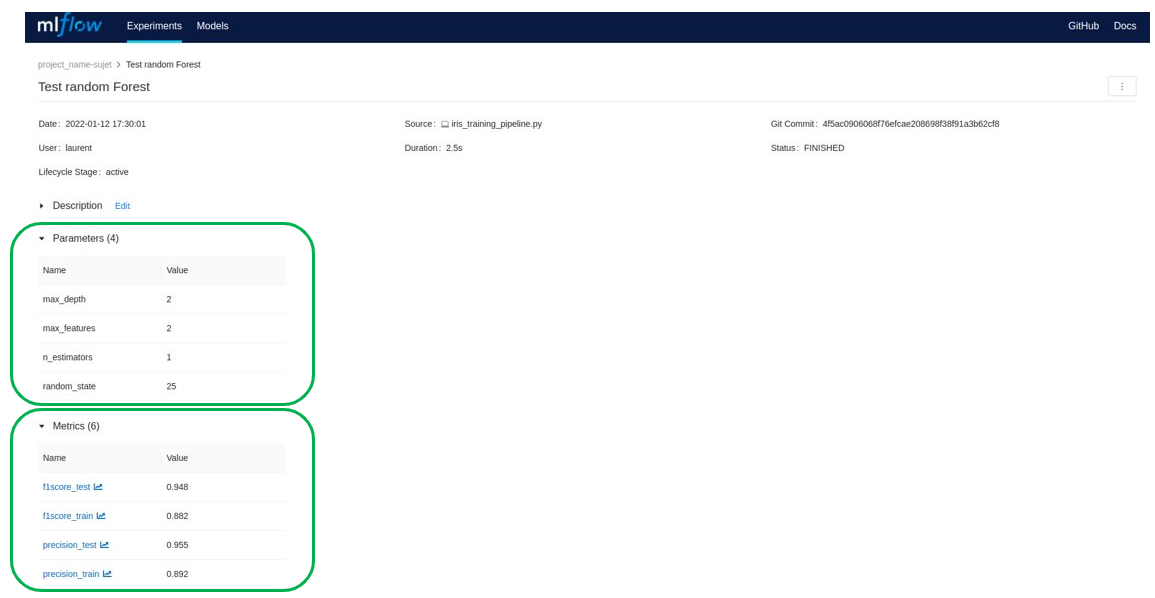
Es posible consultar los detalles de un experimento: los parámetros, los resultados, los paquetes Python utilizados…
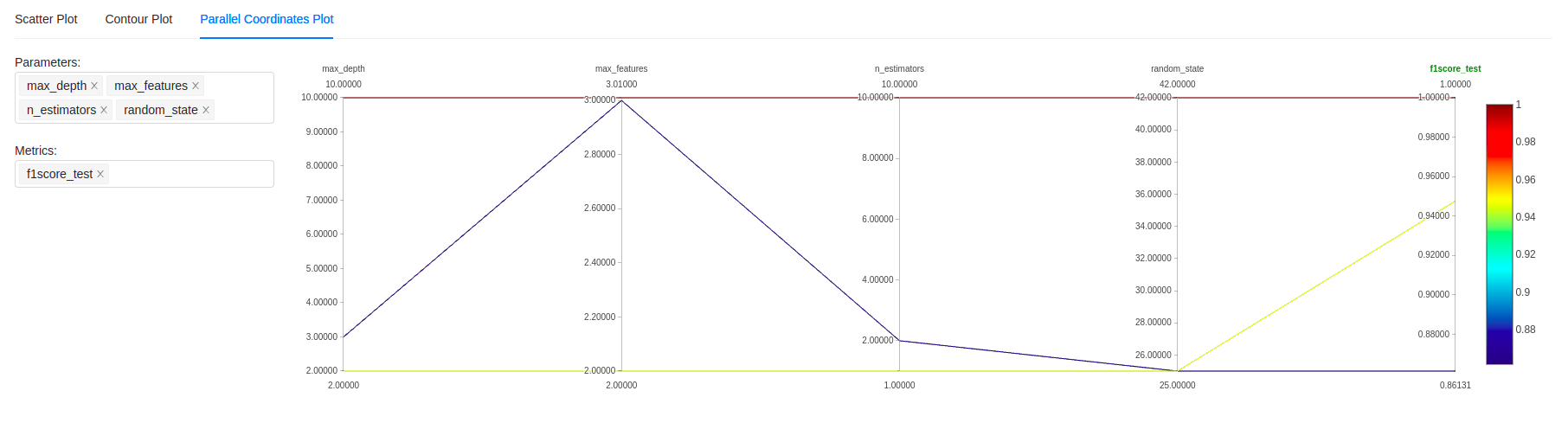
También es posible comparar experimentos de forma más precisa utilizando diferentes tipos de gráficos, incluido el clásico «parallel coordinate plot», que se puede ver a continuación:
Paso 4 – generar el modelo de producción
Si las pruebas han sido concluyentes, el modelo de producción debe generarse realizando las modificaciones de código necesarias y luego trazando el resultado final.
Posteriormente, el modelo debe registrarse en el registro de Modelos a través de MLflow:
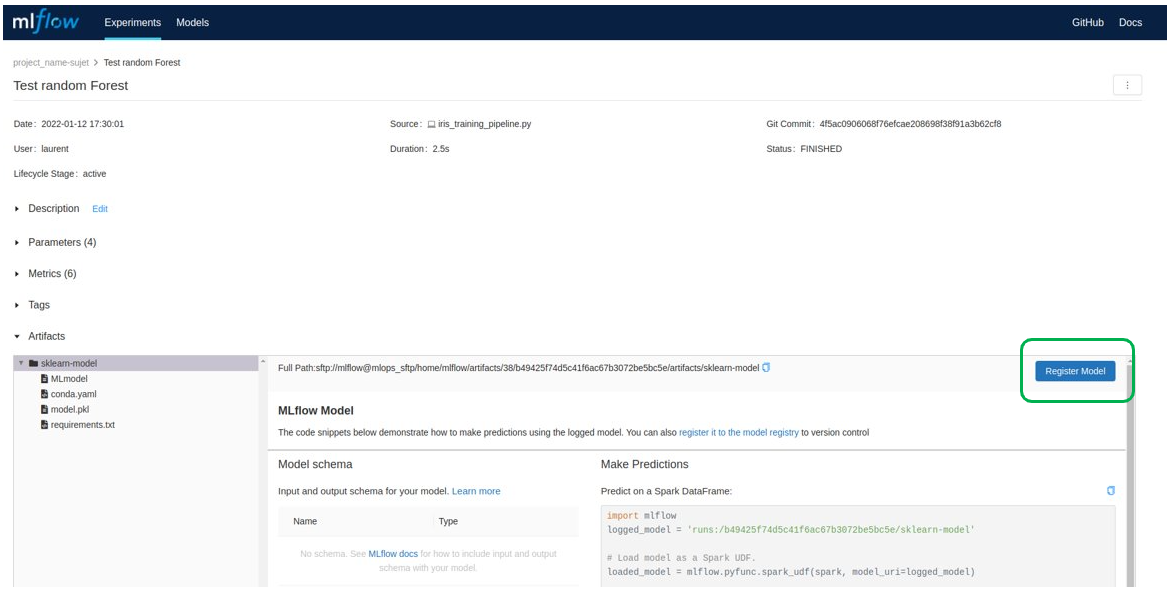
Por tanto, se puede cargar en el código mediante la API de MLflow. El modelo y el código necesarios para su funcionamiento deben integrarse después en el código de producción.
C) Énfasis en el uso de nuevos paquetes
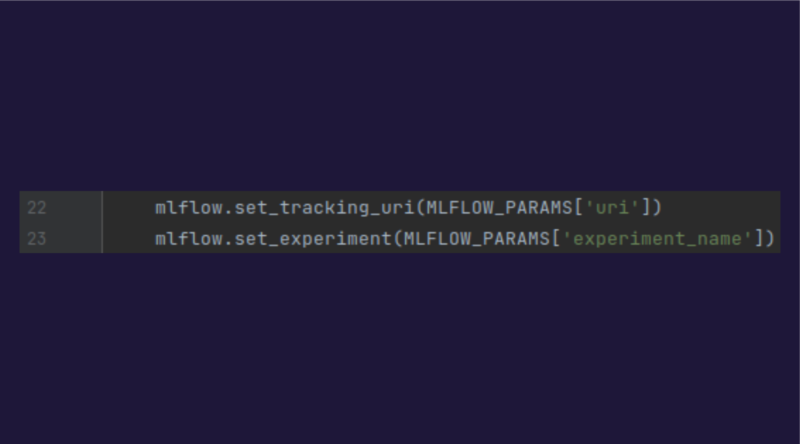
1.MLFlow
Para usar MLflow, es necesario iniciar el entorno de MLflow indicando la uri del servidor de MLflow, así como el nombre del experimento:
A continuación, es posible trazar fácilmente lo que desee utilizando los métodos apropiados:
- log_params
- log_metrics
- sklearn.log_model
- …
Por tanto, resulta sumamente sencillo trazar todo lo necesario.
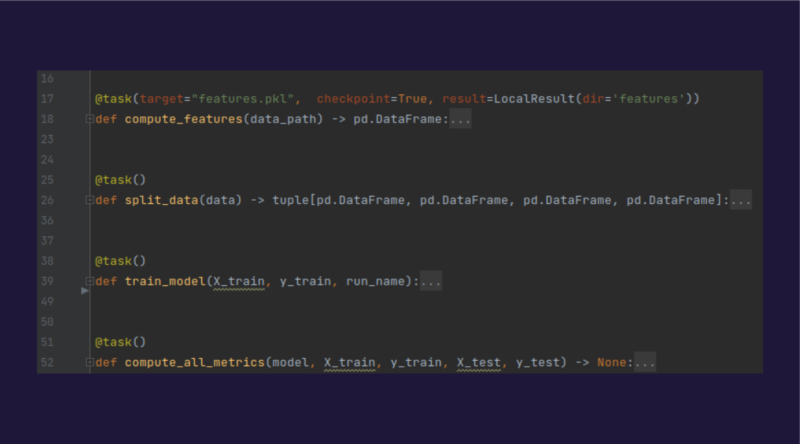
2.Prefect
El uso de Prefect en nuestro contexto permite sobre todo estructurar el código para facilitar el mantenimiento y reentrenamiento de los modelos.
Cada entrenamiento se divide en tareas, cada una de las cuales corresponde a una función, y el conjunto constituirá un pipeline.
Para crear una tarea, solo hay que seleccionar la función que se desee mediante «@task»
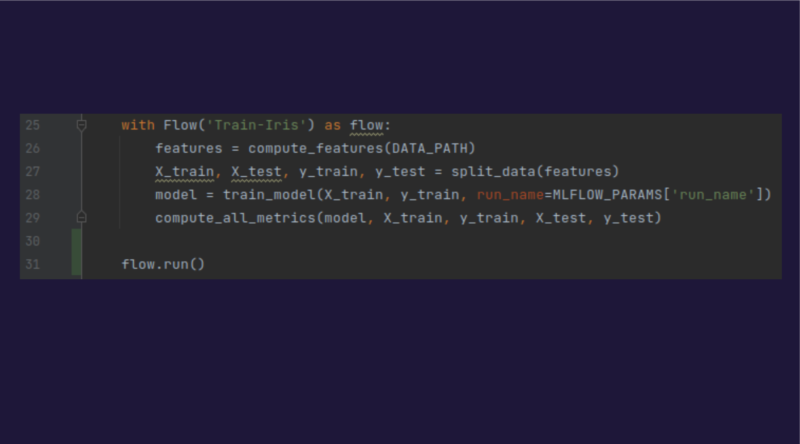
Para crear el pipeline, únicamente es necesario crear un «context manager» que encadenará las tareas y las ejecutará:
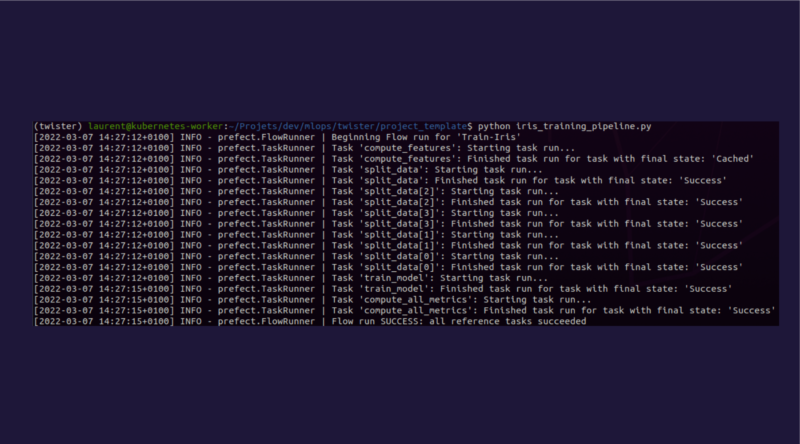
Por último, se debe lanzar el script Python correspondiente.
4.Comparativa costes
Resulta interesante comparar los costes en los tres escenarios: sin industrialización, con la solución que hemos planteado y utilizando una solución en la nube.
1. Sin industrialización
En el caso de que no exista industrialización, los costes se generan principalmente por el tiempo perdido por los data scientists en sus tareas cotidianas:
- Ingresar manualmente puntuaciones y metadatos de entrenamiento
- Tratar de reproducir la línea de base del proyecto o los últimos resultados que correspondan al modelo actualmente en producción
- Probar los algoritmos que ya se hayan probado anteriormente
- Administrar manualmente conjuntos de datos para guardarlos en un espacio compartido y respaldado
- Volver a entrenar modelos manualmente
- …
Resulta difícil estimar la cantidad de días perdidos por año, todo depende del contexto y los tipos de proyectos… Sin embargo, es legítimo pensar que es una auténtica pérdida de tiempo que debería dedicarse más bien a tareas que aporten valor: monitorización, mejora de modelos, mejora de código…
2. Con una industrialización in-house
Los costes relacionados con la implantación de la solución a nivel interno como se describe anteriormente se distribuyen en varios elementos:
Un coste inicial que corresponde a:
- La implantación de la arquitectura técnica de la solución en OpenShift, que se estima en tres días
- Adaptación del código de proyectos existentes, estimada en cinco días por proyecto (por supuesto, depende de cada proyecto)
Posteriormente, los costes operativos correspondientes a la administración y la operación de la solución, que se estima en diez días al año, y los costes relacionados con el hosting y OpenShift, que se estiman en 1500 euros al año.
3. Con una solución en la nube
Con una solución en la nube existen, como en los casos anteriores, los costes asociados a la adaptación del código de los proyectos existentes.
Después están los costes mensuales de la herramienta de aprendizaje automático, que varían de un proveedor a otro; si tomamos el ejemplo de ML Studio de Azure, con 4 vCPU y 16 GB de RAM, esto equivale a 192 dólares al mes por data scientist según https://azure.microsoft.com/en-us/pricing/calculator/ (sin contar los costes de almacenamiento, red, etc.).
5. Conclusión
La herramienta favorita de los data scientists ha sido durante mucho tiempo Notebook, que, si se usa sin rigor, puede desordenarse rápidamente y hacer que la deuda técnica aumente vertiginosamente.
Las herramientas de MLOps permiten enmarcar el trabajo del data scientist y, en última instancia, facilitarle la vida. Si bien es cierto que requiere un coste inicial para migrar los proyectos y configurar la infraestructura adecuada, las ganancias potenciales son significativas: un mejor seguimiento para comprender mejor y optimizar mejor sus modelos, por no mencionar las ganancias en términos de mantenibilidad de los proyectos y de trabajo en equipo.