Euler, ChatGPT y bucles
¿Y si consideráramos de otra manera el código que producimos?
Me incorporé a Davidson hace 9 meses como “desarrollador right tech”. Mi objetivo era conciliar mi actividad profesional (desarrollador) con mis convicciones personales (¡sí, intento ser ecológico! y mis anteriores cometidos en el sector de la automoción provocaban cierta disonancia cognitiva).
Davidson tenía claras sus intenciones, pero la tarea de crear una hoja de ruta definida recayó en mí. Muy pronto se nos ocurrió la idea de crear una herramienta de medición del impacto energético basada en múltiples criterios: tengo mis inquietudes acerca del gasto (de energía, de hecho) causado por la herramienta en comparación con las ganancias potenciales…
Pero este no es el tema del día (un próximo artículo hablará de los resultados obtenidos) porque de lo que me gustaría tratar aquí es de cómo esta nueva actividad me ha hecho evolucionar en la cuestión de la revisión de código y en particular en las repercusiones de la forma en que programamos …
Una mañana, ante este extracto de código…

… lo primero que me vino a la mente fue: “¡¿Pero, por qué demonios vas a inicializar variables si vas a salir de la función justo después, sin usarlas?!”.
Entonces me di cuenta de que, en unos meses, a fuerza de sumergirme en manifiestos de programación verde, artículos diversos (no solo centrados en el código, por cierto) y cuestionarme a mí mismo, había terminado por activar un mecanismo automático de rastreo de lo inútil.
Unos días más tarde, se empezó a hablar de ChatGPT en las salas de chat de Discord de Davidson: empezamos a ver algunos experimentos.
Entonces a Rémy se le ocurre la excelente idea de poner a prueba el “bot” enviando un problema proveniente de la base de datos de Euler y modificándolo para solicitar la producción de un programa en Rust.
Y, debo decirlo, es difícil no asombrarse por la respuesta obtenida:

Según la orientación de las preguntas (adición de optimizado, eficiente, etc.) la respuesta varía un poco, pero la lógica de los bucles anidados siempre está presente.
En resumen, tras un bonito copiar/pegar y algunos ajustes de sintaxis, se compila, se ejecuta y obtenemos el resultado correcto. Todo esto en menos tiempo del que tardo en entender el enunciado del problema… ¡Vaya!
Una primera visión crítica
En mi puesto de trabajo, la ejecución es casi inmediata. El desarrollador que fui en 2021 podría haberse detenido ahí… Pero “rastrear lo inútil” se asocia a menudo a los problemas de optimización y, por tanto, activa los reflejos vinculados a los bucles. ¡Sobre todo porque aquí tenemos 2 anidados!
Por último, puede que haya algo que rascar, y sospecho que puede que no sea tan trivial…
Para ser un poco objetivo, modifico el código para contabilizar el número de iteraciones necesarias para producir el resultado:
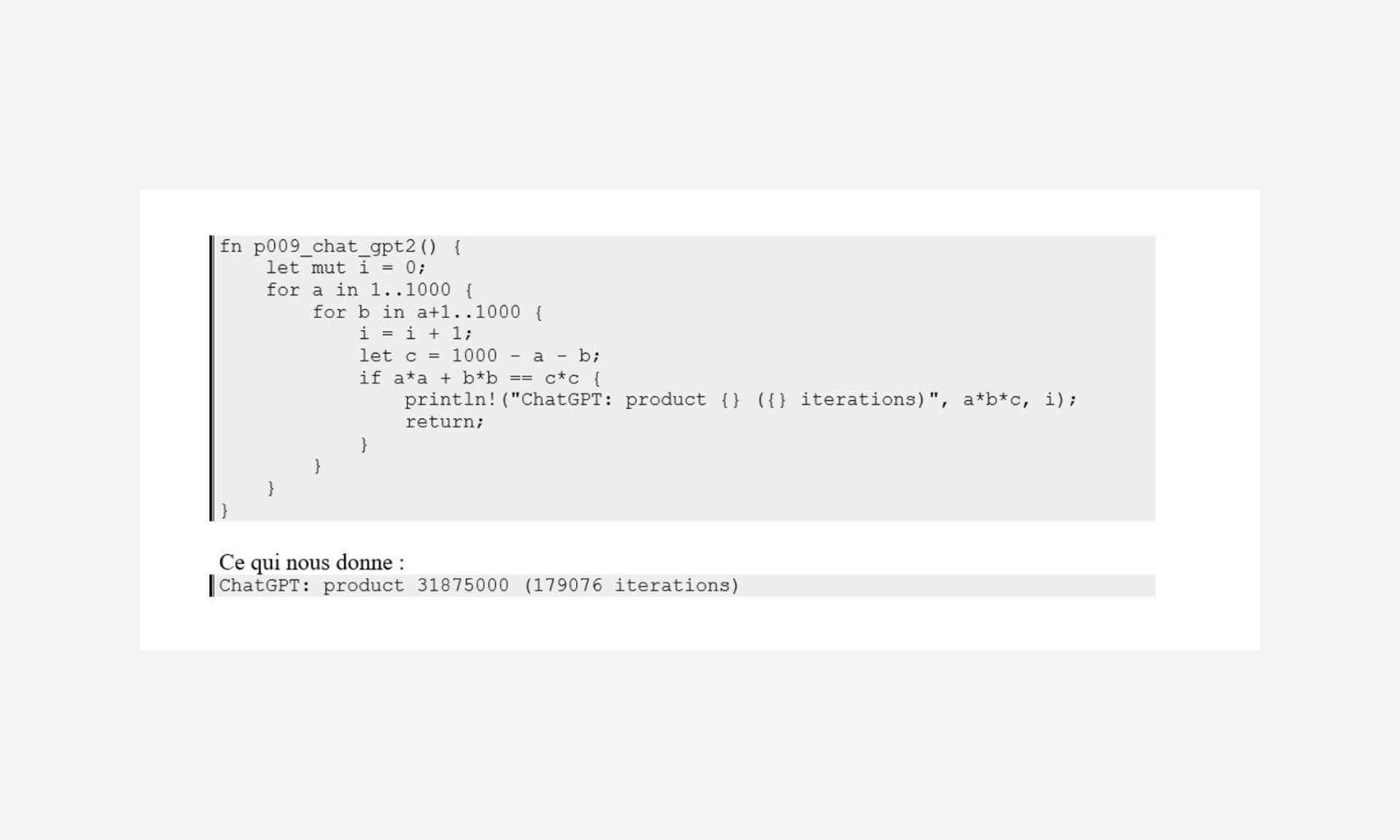
Bueno, bueno, este es un buen punto de partida…
Si nos fijamos un poco más en este programa, podemos ver fácilmente dos trampas clásicas de los bucles:
- Se prueba una lista de valores irrelevantes
- Se superan los límites razonables con valores negativos de c
En resumen, estamos en una aproximación de “fuerza bruta”, un poco optimizada (el segundo bucle comienza en a+1), pero en la que, en definitiva, la aceptación solo es posible gracias a la velocidad de la máquina y a la búsqueda de un orden de magnitud bajo: 1000.
Un poco de depuración solo para mostrar la ineptitud de algunas pruebas:

Por lo tanto, ya podríamos mejorar el caso jugando con los límites de búsqueda, pero lo dejaré para otra ocasión porque siempre habrá tiempo para hacerlo si conseguimos reducir las búsquedas sobre valores relevantes. Con esto me refiero a las ternas pitagóricas válidas.
Reducir el espacio de búsqueda
Una de las mayores optimizaciones posibles de los bucles es, de hecho, reducir el número de casos que hay que probar. Es evidente que probar 10.000 casos potenciales será menos pertinente que probar 100 casos potenciales.
En un caso un poco más “estándar” de programación: si una base de datos permite disponer de un criterio de discriminación que permita restringir el conjunto de datos, la creación de un índice y el filtrado en función de este criterio permiten obtener ganancias significativas.
Pero el filtrado es en sí mismo una operación que tiene un coste y, en nuestro caso, es interesante cuestionarse la propia naturaleza de lo que se manipula, y si existen propiedades particulares.
Una rápida búsqueda en Internet y me encuentro con la “fórmula de Euclides“:

No está mal porque restringirá el campo de búsqueda haciendo bucles sobre los parámetros m y n en “ternas” válidas.
Este es un primer intento de optimización:

Eludir los bucles
En la primera optimización, los límites de los bucles se definen con una dimensión de malla gruesa y, como se observa en la versión obtenida de ChatGPT, debería ser posible reducir el número de casos definiéndolos correctamente.
Pero en lo que es más directamente accesible, es fácil decir que, si la suma de a, b y c aumenta en cada iteración: una vez que se supera 1000, es posible eludir el bucle variando m para empezar de nuevo con un nuevo valor de n.
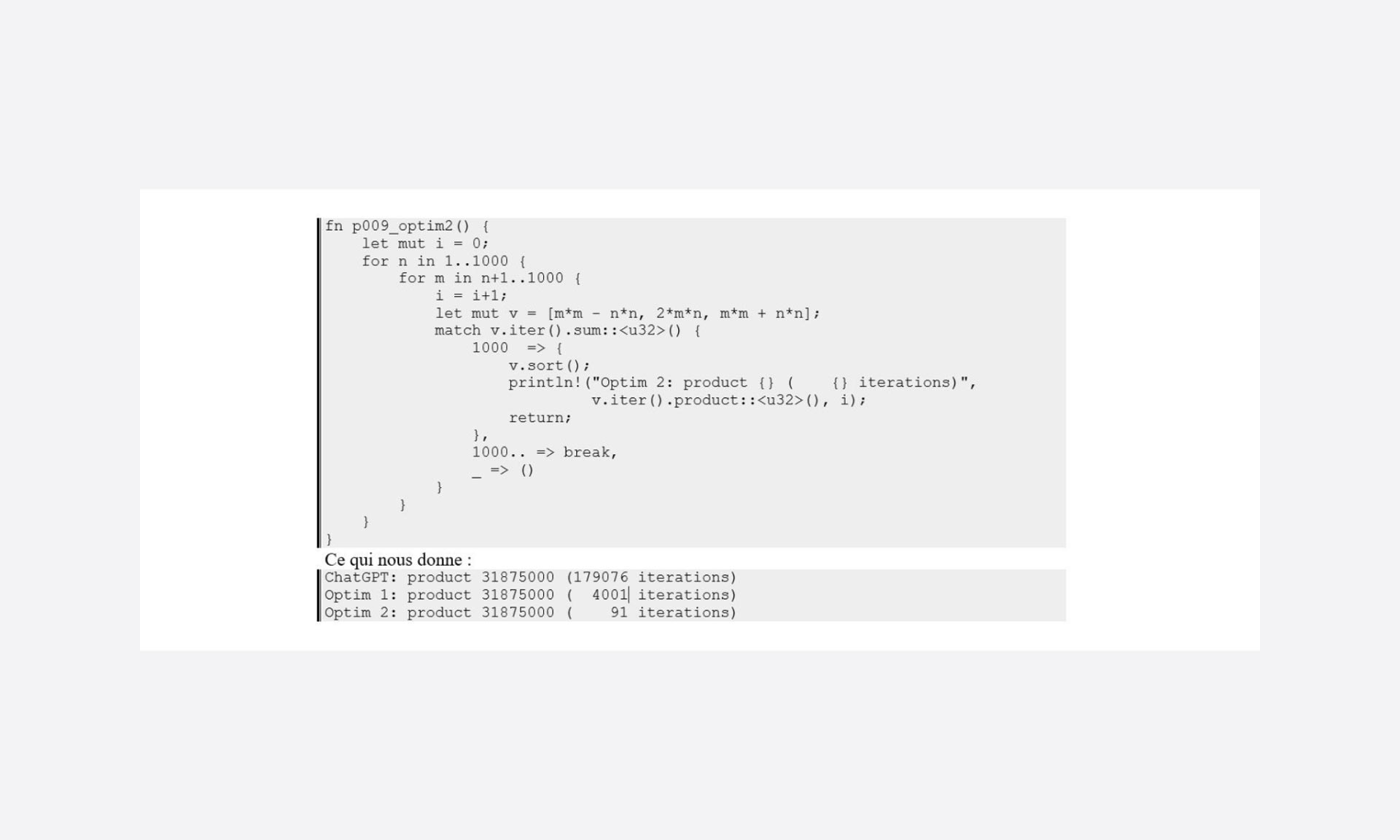
re “¡Toma ya!”
Esta es otra buena optimización, pero solo funciona si se enfrenta a suites de pruebas incrementales.
Pero, solo en lo que se refiere a las condiciones de salida del bucle, la ganancia es más que significativa.
Eficacia del método de investigación
A pesar de la drástica reducción del número de casos que hay que probar para llegar a la solución, nuestro programa sigue probando todos los casos posibles en modo incremental.
Pero el hecho de que estemos trabajando en algo ordenado nos permite plantearnos el uso de distintos algoritmos de búsqueda. Dada la amplitud de los datos (1000) se puede intentar un enfoque binario.
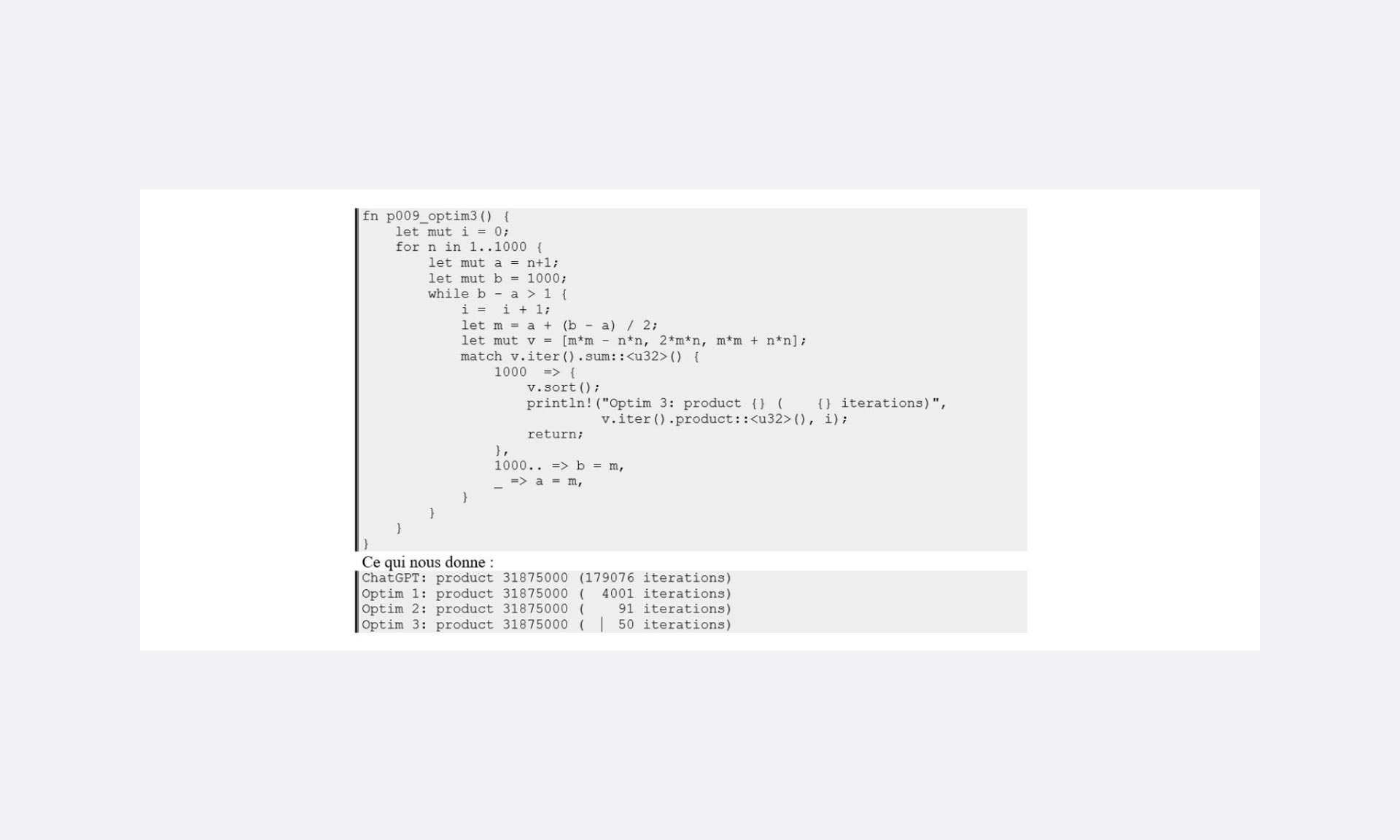
re, re “¡Toma ya!”
Una pequeña ganancia, pero aun así representa un 45 % de la optimización 2. (Nótese que el propósito de la optimización 2 queda anulado por el uso de este tipo de búsqueda, no le quita interés simplemente no es aplicable en este método de búsqueda)
En cuanto a los algoritmos de búsqueda, su complejidad, su interés, Internet está lleno de artículos sobre el tema y numerosas bibliotecas los ofrecen de serie.
La cuestión aquí es que, en el caso de las listas, de bucles ordenados, dependiendo del rango de datos, el uso de una ordenación rápida puede ahorrar rápidamente muchas iteraciones.
Refinamiento de límites
Aún con vistas a reducir el número de casos probados, el rango de variación de n y m fijado arbitrariamente en 1000 debería ajustarse mucho mejor.
En este ejemplo, trabajamos en un problema fijado en una suma de la terna a 1000, y como trabajamos en iteraciones crecientes, podemos hacer un cálculo previo de los límites.
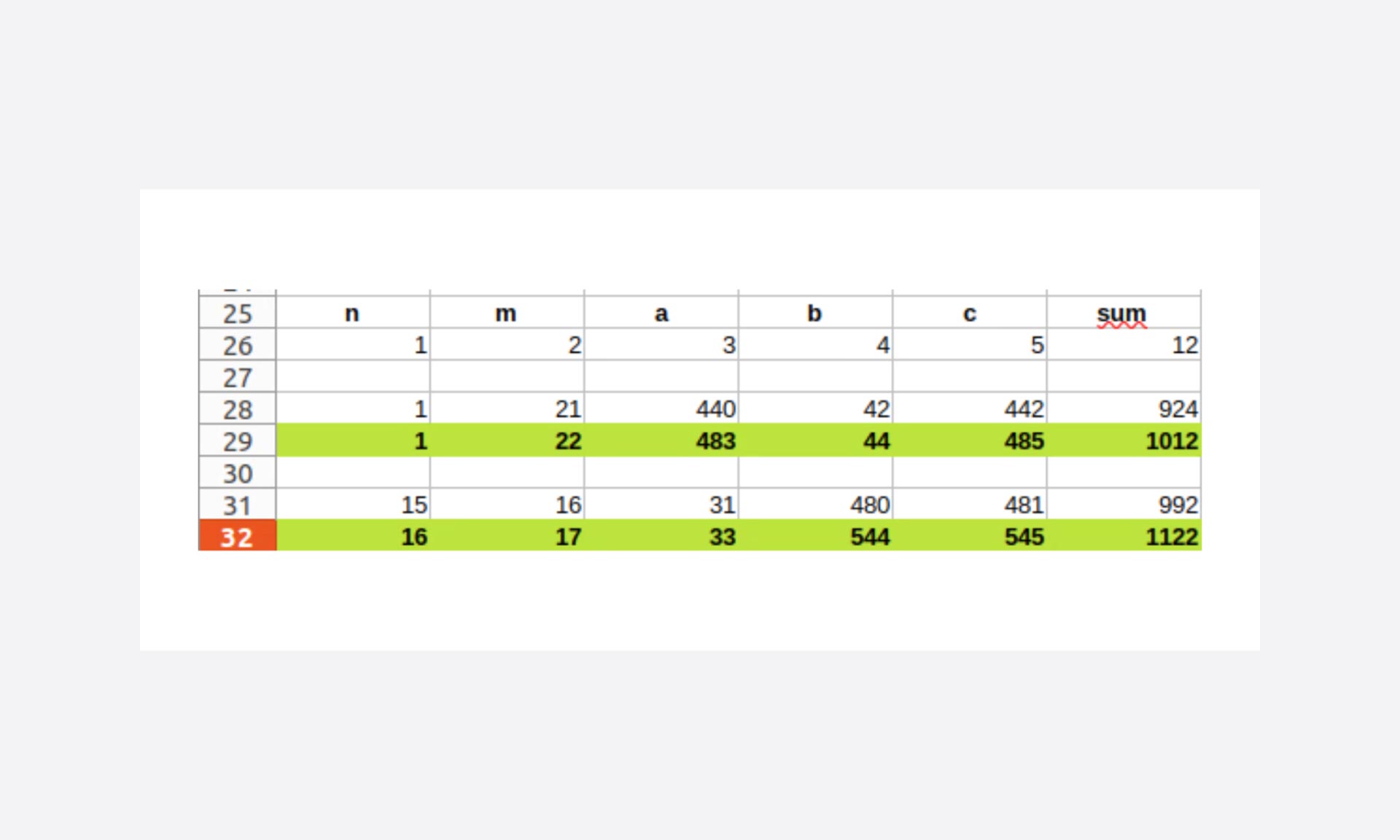
obtenemos rápidamente que:
- En el caso en que n = 1, m debe ser como máximo 22
- El límite para encontrar la solución es con n = 16 y m = 17
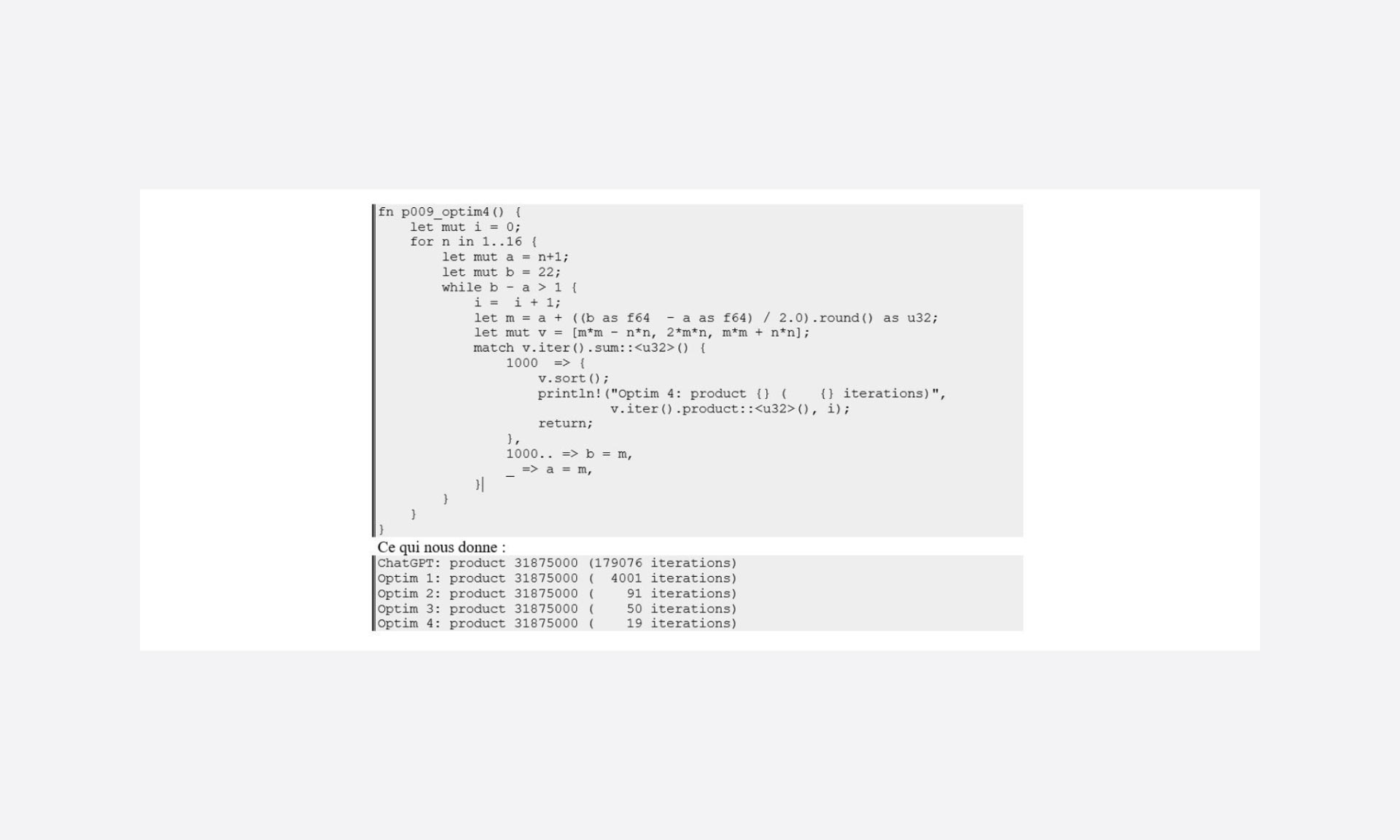
Una buena “delimitación” de los bucles también evita muchas iteraciones.
Rastrear lo inútil
He intentado presentar aquí el recorrido de una mañana de “entrenamiento”: el recorrido no es óptimo y tampoco pretendo que el resultado lo sea (probablemente no tengo suficientes conocimientos matemáticos para ello).
El ejemplo elegido aquí tiene poco interés en la medida en que siempre buscamos el mismo resultado y la potencia de nuestras máquinas hace que esta optimización sea imperceptible en términos de experiencia del usuario (tiempo de espera para obtener la respuesta).
No ocurriría lo mismo si se quisiera utilizar para otras búsquedas: suma de la terna en variable (actualmente de 1000).
Desde el punto de vista de un desarrollador, es importante destacar la importancia de:
- La minimización del conjunto de datos
- El ajuste de los límites de búsqueda
- La utilización de métodos de clasificación/búsqueda
- Eludir los bucles en caso de bucles anidados
Se trata de puntos a tener en cuenta:
- Personalmente, al crear código
- Colectivamente, durante las revisiones del código
Sin embargo, este pequeño ejercicio solo presenta una faceta de la mentalidad “Right Tech” aplicada al desarrollo de software y, en definitiva, solo hice un trabajo de optimización (y esto, simplemente a nivel algorítmico).
Lo interesante radica en que buscamos la optimización sin que esté directamente relacionada con un problema de rendimiento experimentado y percibido.
Y este es el cambio de paradigma contemporáneo destinado a anticiparse a la reducción de los recursos tratando de explotarlos de la mejor manera posible, para compartir más, obtener más riqueza.
La informática y el código son demasiado engañosos en este tema, porque en realidad estamos en un contexto en el que, mientras la experiencia del usuario no parezca penalizada, no buscamos el uso correcto de la potencia puesta a disposición. Y por último, no estamos realmente lejos de los mecanismos que retrasan la concienciación ecológica.
El corolario puede resumirse vergonzosamente en dos puntos:
- Tenemos que reeducar nuestra forma de ver el código para identificar lo que es superfluo (y podemos utilizar herramientas como Ecocode)
- Nuestros “gestores” y nuestros “clientes” también deben darnos tiempo para hacer este trabajo (por ejemplo, en forma de indicadores que ocupen su lugar junto a los clásicos de calidad, costes y plazos).
La parte del software es sin duda la que menos impacto tiene en términos de huella de carbono, pero prestar esta atención a la búsqueda de lo innecesario a la hora de diseñar e implementar el código repercute directamente en la obsolescencia del hardware, ya que lo utilizamos de forma más eficiente.
Para los curiosos, hice una prueba buscando la terna con una suma de 50000…
| Búsqueda de la suma de la terna 5000 | |||
| Iteraciones | SegundosJulios | ||
| ChatGPT | 449953751 | 9,37 | 113,059315 |
| Optim 4 | 512 | 0,11 | 0,419751 |
Segundos mediante la herramienta unix time, julios mediante la herramienta vjoules de powerapi
Os dejo con el ejercicio del orden de magnitud, teniendo en cuenta que, en informática, el tiempo es energía consumida.
¿Y si entrenáramos a ChatGPT para que tuviera en cuenta las cuestiones de ecodiseño a la hora de producir código?